

Impact of using HTTP connection pooling for PHP applications at scale
By Giuseppe Lavagetto, Principal Site Reliability Engineer, The Wikimedia Foundation
The challenges of running PHP applications at a large scale
PHP is a very successful language, if not a loved one. It powers many of the most visited websites in the world, including our wikis. MediaWiki, the software that runs our sites, and 100,000s of wikis worldwide, is written in PHP.
The reason for PHP’s success can be traced back, according to Keith Adams, to three salient characteristics of the language—which are really characteristics of its runtime:
- Scoping: all state is local to a request, and by default, all requests share nothing with each other. Every resource that is allocated during a request gets thrown away at its end. There are mechanisms like APCu that allows the use of a shared memory segment, but the complexity is hidden from the developer.
- Concurrency: given each request is isolated, concurrency is free in PHP. You can respond to multiple requests in parallel without any sort of coordination between threads.
- Development workflow: since there’s no persistent state and no compilation step, you can quickly check your work while developing a web application by editing the code and immediately refreshing the page, without restarting anything.
The scoping rules are both a blessing and a curse for a high traffic website. Not being able to share anything between requests means you can’t have things like connection pools so that whenever PHP needs to connect to any external service (be it a datastore or another HTTP application), it needs to initiate a new upstream connection.
Sometimes the cost of establishing a new connection is so high that it has a significant impact on the performance of the application. This problem is common among large-scale websites, so for example HHVM, the PHP/Hack virtual machine created by Facebook, implements connection pooling for curl requests. As longtime users of HHVM, the built-in connection pooling was of utmost importance to us in mitigating the performance penalty when calling services via TLS over a network link with non-negligible latency—say another datacenter.
Given that HHVM has moved away from 100% compatibility with PHP, last year we migrated our MediaWiki installation from HHVM to PHP 7. The migration was a success, but we encountered a number of differences that had significant impacts, both positive and negative. Specifically, PHP 7 lacks facilities to create HTTP connection pools for its curl extension.
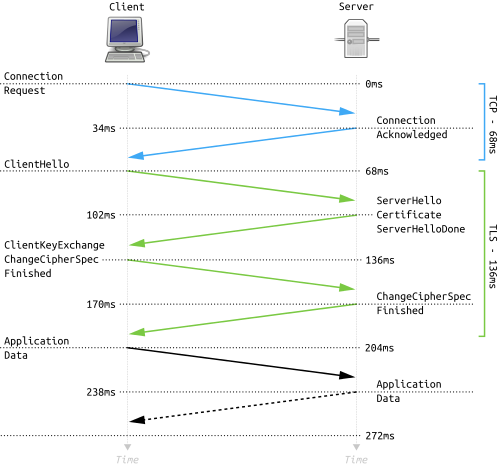
We measured the latency impact of having to establish a new connection for every encrypted request across datacenters to be in the order of 75 milliseconds—which is what we expected given establishing a TLS connection requires 2 additional round-trips compared to a non-encrypted TCP connection.
{kind=link}
A service to manage outgoing HTTP requests
Enter Envoy, our TLS terminator of choice. Envoy is much more than just a reverse proxy: it’s designed to be a service middleware. It’s intended to work as a connective tissue between services in modern infrastructural stacks (aka, “cloud-native” stacks). Since Envoy has efficient built-in support for connection pooling, it seemed that introducing it as a proxy not just for incoming requests to provide encryption, but also for outgoing requests, could help us close the performance gap, by cutting out the TLS connection overhead from each request.
The impact of persistent connections: a simple test
First, we wanted to measure performance with a simple benchmark—fetch the banner page of ElasticSearch (the software that powers the Wikipedia search box), a small JSON document, via a PHP script and measure the number of requests per second sustained over a fixed concurrency while varying the way we connected to Elasticsearch.
The results were unequivocal. While using encryption caused a severe performance degradation, introducing Envoy as a local sidecar, called via HTTP to mediate HTTPS requests to the ElasticSearch cluster produced a 46% throughput gain compared to unencrypted direct connection, and a 120% gain compared to direct connections using HTTPS. This may be counterintuitive: adding an intermediary process made the outbound connection much faster—even compared to the baseline with no TLS at all!—because the local Envoy was able to reuse its sessions with remote ElasticSearch hosts.

These results—while not fully representative of real-world situations—looked extremely promising: we had a path forward for mitigating the performance penalty of encryption over higher latency networks.
The effect of using Envoy on our applications
So, we proceeded with the second phase of our transition, using Envoy as a proxy to manage HTTP requests that MediaWiki performs to other services, prioritizing services that were already called via TLS. One such service is sessionstore, a REST service that stores user sessions for MediaWiki; this service now powers all of our wikis, and receives around 20 thousand requests per second. At the time of the transition, it was serving only a portion of the wikis, and thus racking up around 4500 req/s. We expected that not having to establish 4500 TLS connections would save us some network traffic and some CPU churn for the service even if the network latency was small. The actual effect we observed was still surprising: the CPU usage for the application went from 2.5 CPU cores to circa 0.8 CPU cores as soon as we deployed the configuration change.
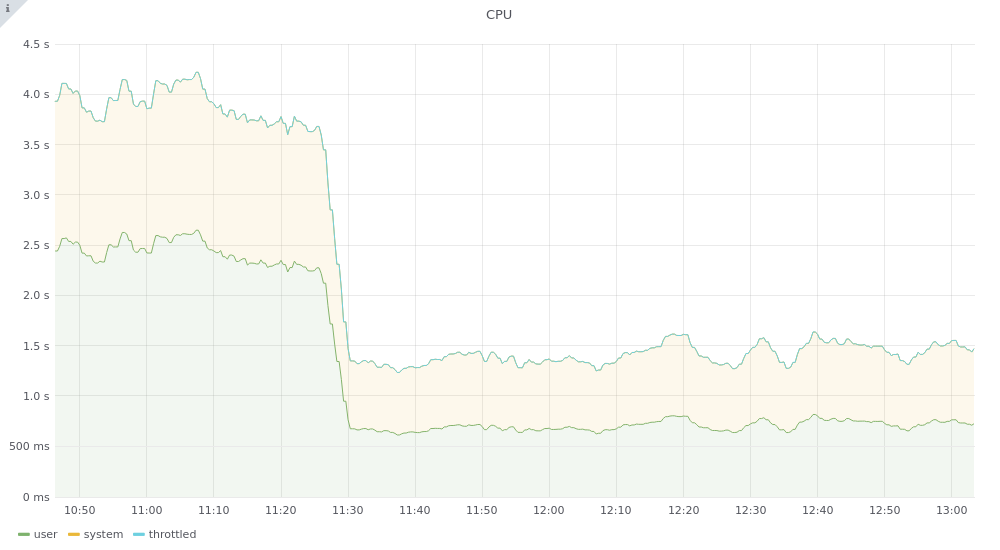
Basically, 70% of the resources used by the service were spent to instantiate a new TLS connection for each request! We also expected to see a reduction in the network traffic, as not only the whole TLS handshake procedure would happen for a fraction of the requests, but the service didn’t need to send out its TLS certificate 4500 times per second. Even if the certificate is just 1.67 kb, sending it 4500 times per second means we’re sending about 7 MB/s of data just for that. And indeed, the effect was quite impressive.

As you can see, the reduction in bandwidth happens for both received and transmitted bytes.
While these results are remarkable, they are of little interest to our users if their experience does not improve as well. Fortunately, we did expect this change to have an effect on the performance of both the service (as it could answer requests without the TLS overhead, which is not negligible even over a local network where latencies are a fraction of a millisecond) and of MediaWiki itself. The net result on the service can be seen by a graph of its responses, stacked by latency bucket:

The number of responses taking less than 1 millisecond to complete (in green) doubled and the long tail of responses over 5 milliseconds (in red and violet) almost disappeared.
As for the effect on MediaWiki, the number of requests that returned in less than 100 milliseconds rose by 12%. This is a significant gain, more so if we take into account that the switch only affected a portion of our traffic.
The performance increase is so notable that it allowed us to make MediaWiki call all services with encryption, without risking the severe degradations of service performance that we had experienced after the migration from HHVM to PHP any time we had MediaWiki call services cross-datacenter.
Conclusions
Introducing a service proxy like Envoy between a PHP application and other services allowed us to create connection pools and thus reduce the latency and cost of calls between the application and other services. As shown, the gains we obtained were large enough to be noticeable in the overall latency of the application.
We had further reasons for choosing Envoy, —the ability to introduce rate-limiting, circuit-breaking, and observability to a microservice architecture in a consistent manner. We’ll take a deeper look at these in another post.
Our experience shows that anyone running PHP applications in a microservices architecture can obtain immediate performance and stability benefits by adding an efficient connection pooling proxy between the application and other services. In particular, if you run your applications in the cloud over multiple availability zones, or from multiple datacenters as we do, the performance improvements are probably going to be noticeable to your end-users.
About this post
Featured image credit: JNEM detail, Daniel Schwen, CC BY-SA 4.0
{kind=link}
Why did you choose Envoy over using Nginx (which is currently set as your web server)? Nice performance gains either way!