Explore wiki project data faster with mwsql
By Slavina Stefanova, Wikimedia Cloud Services
The mwsql library is the latest addition to MediaWiki-utilities, a collection of lightweight Python tools for extracting and processing MediaWiki data. It provides a simple interface for downloading, inspecting, and transforming SQL dump files into other more user-friendly formats such as Pandas dataframes or CSV. mwsql is available through PyPI and can be installed using pip.
Why mwsql?
Data from Wikimedia projects is open-source licensed and publicly available in a variety of formats, such as:
- Data dumps in SQL, XML, and HTML format
- Database replicas thorough Toolforge, PAWS, or Quarry
- API endpoints
While utilities for working with most of these data sources have existed for quite some time, for example mwapi and mwxml, no such tool existed for SQL dumps. Because of this gap, developing mwsql was proposed as a joint Outreachy project between the Research and Technical Engagement teams during the May-August round of 2021.
SQL dumps
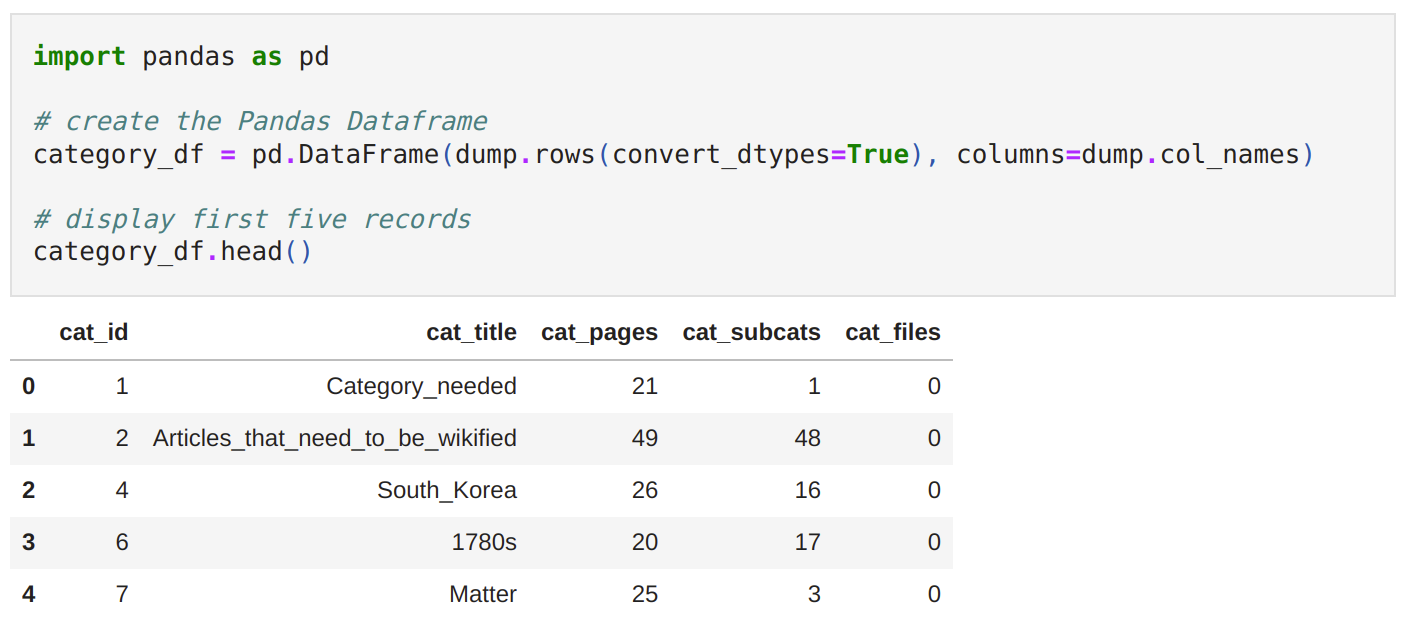
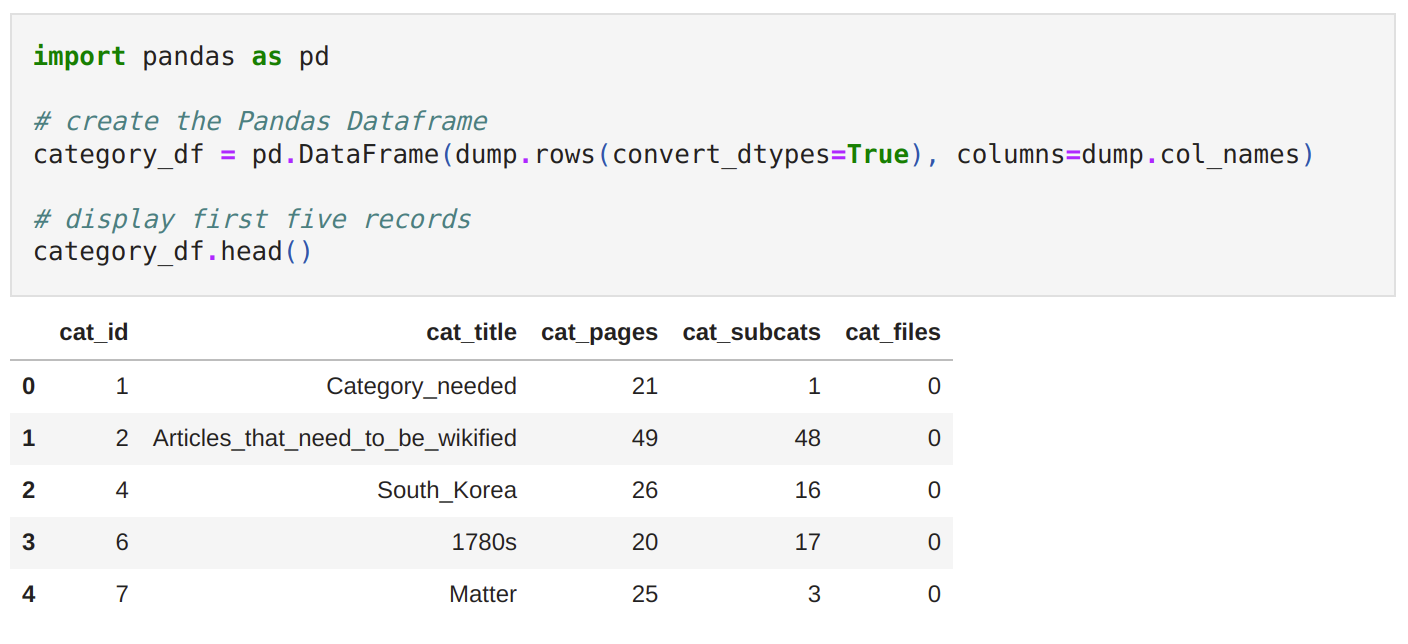
Before diving into exploring the different features of mwsql, let’s take a look at what a raw SQL dump file looks like.
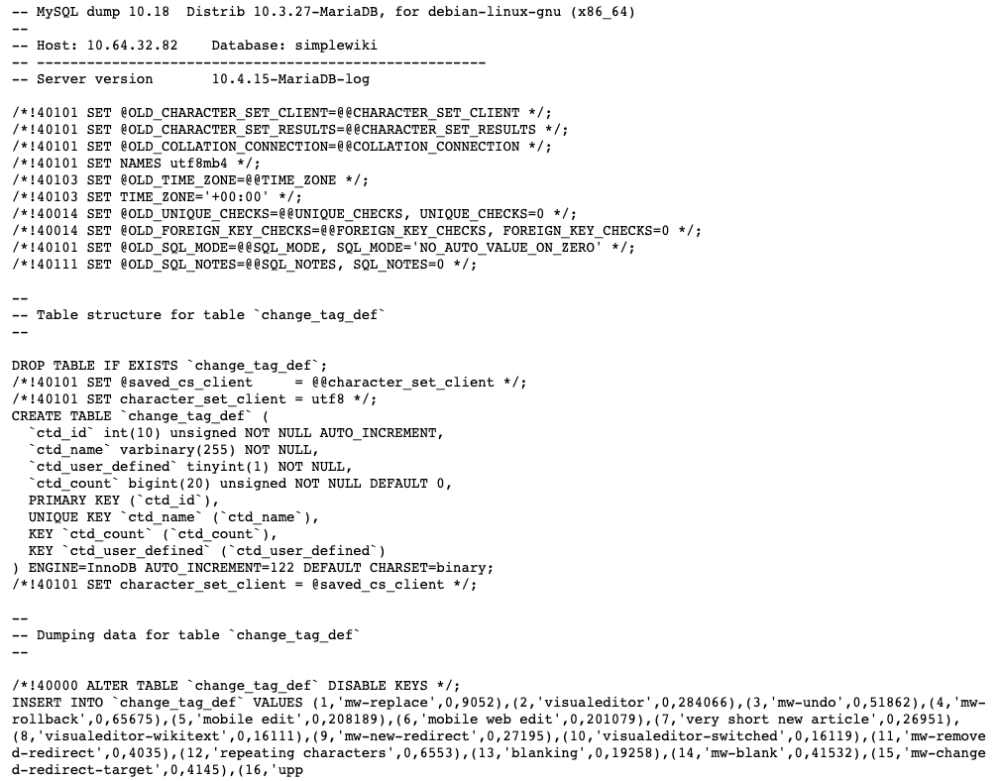
The dump contains information related to the database table structure, as well as the actual table contents (records) in the form of a list of SQL statements. There is also some additional metadata. Database dumps are most often used for backing up a database so that its contents can be restored in the event of data loss. They are not designed to be worked with ‘as is’, e.g., parsed, filtered or searched. However, having the ability to access data directly from the dumps allows offline processing and lowers the barrier for users with only basic Python knowledge, such as data scientists, researchers, or journalists because the only prerequisite is basic Python knowledge.
mwsql features
mwsql main features are:
- easily downloading SQL dump files
- parsing the database table into a
Dumpobject - allowing fast exploration of the table’s metadata and contents
- transforming the SQL dump into other more convenient data structures and file formats
Use mwsql with a wiki data dump
The rest of this tutorial demonstrates each of these features through a concrete example hosted on GitHub. You can clone the Jupyter notebook to go through the example of downloading dump files, parsing the SQL dump file, exploring the data, and writing to CSV.
You’re welcome to clone, fork, or adapt the Jupyter notebook containing the source code for this tutorial to meet your needs.
Future of mwsql
As many of the dump files are huge (>10GB), having to download them before being able to process their contents can be time-consuming. This is less of a problem in a WMF-hosted environment, such as PAWS, where the dumps are available through a public directory. Having the opportunity to inspect a file before committing to download all of it, as well as being able to process it as it is downloading (streaming), would be a huge performance improvement for users working in non-WMF environments.
mwsql project info
The project repository is hosted on GitHub. Anyone is welcome to submit a patch, file a bug report, request new features, and help improve the existing documentation. Have you used mwsql to do something interesting with Wikimedia data? Leave a post on this Talk page, and together we can think of a way to showcase your work.
Further reading
This tutorial explains how you can use mwsql along with other tools from the Mediawiki-utilities suite and Pandas to explore how mobile editing has evolved over time.