

Introducing Database as a Service on Cloud VPS
By Andrew Bogott, Senior Site Reliability Engineer
Introducing Database as a Service on Cloud VPS
The addition of attachable block storage on Cloud VPS has cleared the path for several nifty cloud additions. The most recent of these is Trove, Openstack’s Database as a Service (DBaaS) implementation.
Historically, when users have asked where to put their databases, we’ve never had a perfect answer. Some databases wound up hosted on NFS (which provides dismal IO performance), or on local storage (decent performance but always one crash away from data loss), or borrowed from Toolforge (where they share a single host with hundreds or thousands of other tiny databases.) Trove provides a new path that is almost certainly better than the previous options.
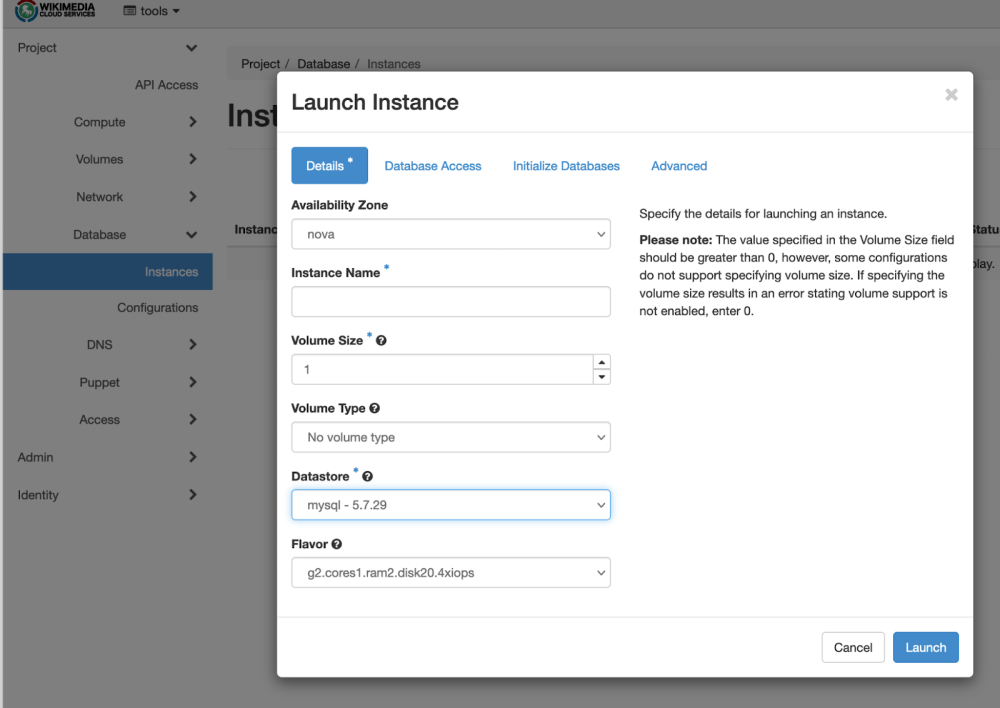
Trove provides a straightforward Horizon UI for creating new databases with a minimum of sysadmin expertise. When the database is launched from Horizon, Trove will create a Cinder volume for data storage and a database instance that runs the actual database engine. Both the backing volume and the engine instance are scalable, so as your data or traffic grows you can add storage or processing capacity without interrupting service or rebuilding your database.
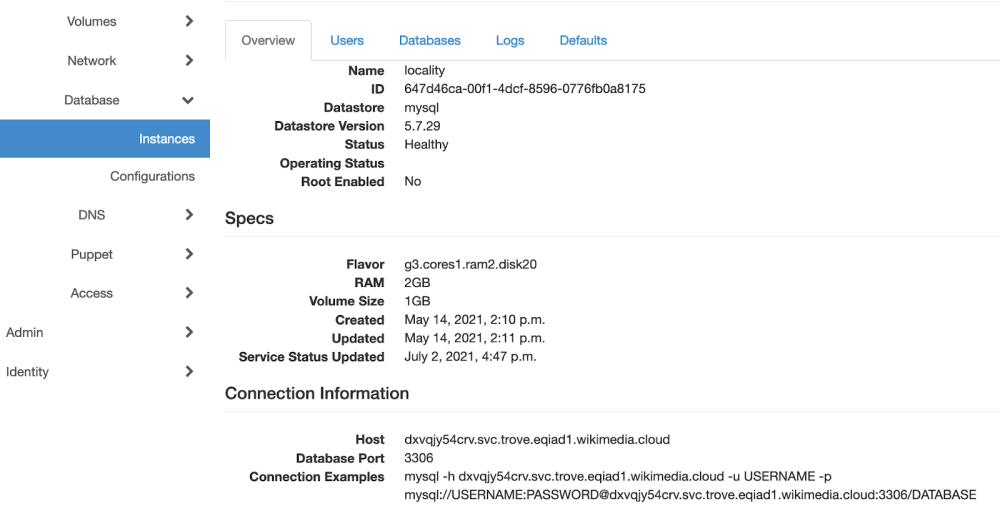
You can then copy and paste the hostname or connection details onto your working server, get a psql or mysql prompt, and get to work. Or, if you prefer, the Trove Horizon UI also supports simple management tasks: creating users and databases and simple grants.
So far, we’ve enabled Postgres, MySQL, and MariaDB backends. A few other backends have been available from time to time with unclear support or reliability; if you crave a different database engine, it won’t hurt to ask.
Trove also supports Horizon-driven replication and backup; both of these features require object storage to work properly, and WMCS doesn’t currently provide an object storage backend. We plan to implement this within the coming year. In the meantime, I encourage users to do periodic backups by hand using something like mysqldump.
Trove databases consume separate project quotas from the existing instance and storage quotas. All projects have small database quotas enabled by default. When you’re ready to use this feature in earnest please open a quota request.
That’s the good news! Now, here’s the bad news:
- This is a new feature, which means that no matter what you do, you will most likely be the first person to do it. Approach with caution, and don’t drop any un-recoverable data onto a Trove database until you have some evidence of stability.
- OpenStack Trove was first released six years ago, so it is not new or experimental. Nevertheless, project adoption has been spotty, and it’s used in only a handful of public deployments. That means that there are likely areas of fragility. The chances are good that we’ll discover use cases that aren’t used by other deployments and break at the first provocation.
- Trove has more than zero active developers working on it but not a lot more. That poses a risk that future releases may degrade. We will need to keep evaluating future releases to make sure that they’re stable and secure. Fortunately, because it uses standard database backends, even a future deprecation of Trove would not result in data loss.
Please give Trove a try, and let us know how it goes!
About this post
Noctilucent-clouds-msu-6817.jpg, Matthias Süßen, CC BY-SA 4.0
{kind=link}
🇮🇳🏸🏆⛈️🏆🌈👍🙏