

Getting the WDQS Updater to production: a tale of production readiness for Flink on Kubernetes at WMF
By Maryum Styles, Software Engineer III, Search Platform, Wikimedia Foundation
We created a Streaming Updater for Wikidata Query Service (WDQS), and it runs on Flink—Awesome, right? The new Streaming Updater will help keep WDQS up and running as Wikidata continues to add information daily. Developing a plan for a new updater was exciting, and deploying the new updater had a lot of lessons learned about Flink in production environments.
Going from Beta to Production
The Streaming Updater was running on YARN in the analytics cluster for the beta users, and we needed to get it to production, aka Kubernetes (K8s). Our Site Reliability Engineering (SRE) team joked that we were deploying a job runner (Flink) on a job runner (Kubernetes).
We thought we could easily deploy a nice Flink application cluster on Kubernetes! No problem, right?—Just bundle that Streaming Updater jar in the existing base Flink image. That’s what the cool kids do.
Haha nope. We had to rebuild the wheel.
Since the Wikimedia Foundation (WMF) K8s cluster only allows base images from the small selection of internal base images, and they don’t allow plain Dockerfiles, we used an internal tool called Blubber. Dockerfiles can vary wildly from developer to developer and in order to have standards around layered filesystems, caching, directory context, obscure config format, and inheritance, not to mention testing, Blubber is used to avoid common pitfalls. Blubber is a fun templating tool that takes your YAML file and turns it into a WMF-approved Dockerfile. Then there’s a WMF pipeline that takes your nice Dockerfile, creates your image, and loads it into the WMF docker registry, which is all pretty nice.
Great! It took some time adjusting the official Flink base image to our needs, but we had an image that we could put in a Helm chart. Now, we were good to go!
Again, not at all.
WMF Helm charts follow certain standards, and there’s a lot of boilerplate bits that are intended to be helpful for people. But for an app that is running another app, they’re not that helpful. The charts were tweaked, merging the best of the Flink K8s docs with the WMF Helm chart standards.
But we still weren’t quite ready.
Flink does stateful computation—and needs somewhere to store said state. Flink doesn’t need to store a ton of data like how a database does, but it does need to store checkpoints that ensure that the data computation happening is secure and consistent. We decided to go with OpenStack Swift since it was already supported by the Foundation. That required adding an authorization for Swift to the Flink filesystem plugin. Failed events and other types of events that didn’t work out can’t be stored in Swift, so those needed to go to Kafka. That happens via the WMF event platform.
And then there’s the whole running in production thing. How would we stop a Flink job when we wanted to update the Streaming Updater job? Could we stop it and have a savepoint? Could we resume from a savepoint? There’s not much we could find online about managing stopping and restarting jobs from savepoints outside of, “make your Flink cluster highly available.”
“Highly available” for Flink does not mean 24/7 uptime. It means that if the job manager is stopped in any way, the job can resume from the last savepoint. That’s great, but that still didn’t answer the question of what would happen if we chose to stop the job (to upgrade, etc).
This is where the Flink session mode comes into play. When you deploy Flink as a session cluster, you decouple the jar from the Flink application. Then you can stop the Flink job with a savepoint without having to take down the whole application cluster.
Just when you thought there were no more blockers: Surprise!
Everything in the WMF Kubernetes cluster has to be deployed in both of our data centers. But Flink isn’t designed for multi-region. Honestly, the whole discussion about working with multiple data centers and how a Kubernetes-powered Flink application might work in that environment deserves a separate blog post on its own, so I’ll spare the details here. In the end, we decided on a solution that puts a separate Streaming Updater in each data center – thanks, to which we didn’t need to worry about pushing the data across the world. It also made more sense to us, because our Kafka instances are mostly separated that way as well (with the help of the Mirror Maker, a part of Kafka that can synchronize topic data between data centers).
Adventures in Production
Deploying the Streaming Updater, while by far the most complicated part of the process, wasn’t all that we needed to do. At the time, WDQS used the old update process and the service itself was serving live traffic.
The initial plan we came up with was relatively easy:
1. Depool (remove from the load balancer) a single data center.
2. Disable the old updater.
3. Reload the data on all hosts.
4. Enable the new Streaming Updater.
5. Pool that data center back.
6. Repeat for the other data center (simplifying step three by copying the data from the already migrated data center).
Unfortunately, it turned out there was a flaw in this plan. So far, we assumed that a single data center could handle all the traffic. It turned out that that isn’t always the case and turning off a data center in a way that it cannot be immediately plugged back in could result in a catastrophic, long-term WDQS failure.
In light of that, we decided to change the approach and plug out one host at a time to transfer the data from another, already migrated host. It meant some inconsistencies along the way —the old updater was known to lose updates and the new one fared much better, but that sounded better than potential (and probable) service-wide downtime.
In the end, we were, again, surprised by the performance of the new solution. While we had some initial delays to the migration process, once started, it actually went much faster than we expected. The post-import catch-up took 24 hours compared to the two weeks usually required by the old system. Then the rest of the process to replicate the Blazegraph data across the server fleet was done in four workdays, about half the time we assumed it would take!
Work that started more than a year and a half before (with the research phase starting way before that), was finally done.
It’s somewhat hard to celebrate remotely, but due to an amazing feat of logistics, all around the world (Thanks, Janet! 🙏 ), we got cupcakes 🙂

(Not) out of the woods
The Streaming Updater is meant to be a more stable, scalable, and consistent solution to our update process. It’s now been deployed for more than two weeks and it’s clear that it already fulfilled at least part of that promise.
We decided that with the current setup, our Service Level Objective (SLO) for WDQS is to have an edit latency under 10 minutes at least 99% of the time. The graph below shows the fulfillment of that objective, calculated over a day for a period of 90 days. The vertical blue line denotes the last instance’s deployment of the new Streaming Updater on 18 Oct 2021 – note that the instability after that is caused by the one-day calculation period.
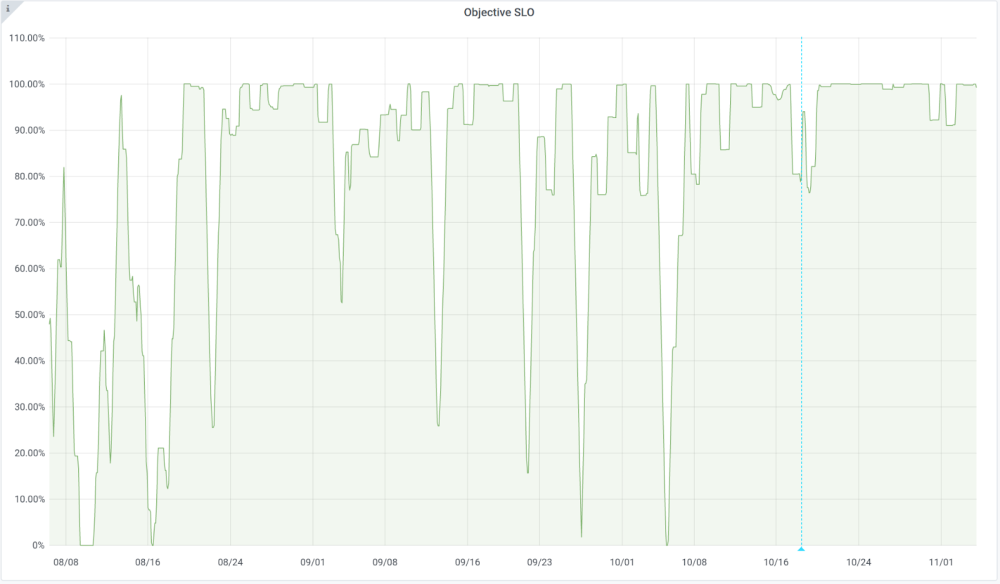
It’s clear that the stability is better, at least so far. It’s not perfect yet, because our backend, Blazegraph, still has its issues and affects the latency in general, but the Streaming Updater is doing its job.
What would we do differently?
Looking back, we should have started with a Flink session cluster and not worried so much about bundling the Streaming Updater jar. That takes away a lot of network dependencies and other ephemera. We were so focused on the Streaming Updater application that we allowed that to drive all of our decisions. Of course, there are needs that are new updater-specific that do matter, but just getting Flink working first would have made some things more apparent.
It felt easier to have a barebones version of Flink that was used for Beta testing running with YARN. It takes one line to spin up a Flink cluster, but that cluster in no way is ready for a production environment. Focusing on having a production suitable Flink cluster earlier would have been better since we had to end up changing our application architecture to accommodate different production requirements, like multi-datacenter and using Swift.
Everything else that came up didn’t really feel like something we could have known about before. If you’re thinking of getting Flink deployed in your production environment, I would see if it’s possible to have a separate K8s cluster for it. Of course, all of our applications are namespaced, but Flink as an application has different security concerns than the average application.
Flink is complex and so is Kubernetes, so putting them together is not the simplest process, along with the other moving parts of storage and multiple datacenters. Figuring out the Flink job lifecycle and maintenance has been tricky, especially for a long-running job, but overall better than having an update script that leaves stale data in the Wikidata Query Service.
Deploying a stateful application can be tricky, but the benefits of Flink and being able to scale the update process is worth it. With Flink, WDQS will be able to receive updates as they happen which means less load on Blazegraph since updates are incremental versus handling a bunch of changes at once from a dump. The knowledge gained from using Flink with Kubernetes will be helpful to the Foundation, since other teams have been following this process carefully and hope to utilize Flink for their own solutions.
About this post
Featured image credit: File:Elakala Waterfalls Swirling Pool Mossy Rocks.jpg, Forest Wander, CC BY-SA 2.0
{kind=link}
This is part three of a three-series. Read part one here. Read part two here.