

How we learned to stop worrying and loved the (event) flow
By Zbyszko Papierski, Senior Software Engineer
How hard can that be?
Wikidata Query Service (WDQS) is probably the most common way to access Wikidata—well, data. It’s basically an open SPARQL endpoint, so it allows everybody (and I do mean everybody) to ask for any data contained within this vast graph of knowledge. You want to know about all the famous cats? Check. List of all Pokemon? Here’s your very own Pokedex! Why not go a bit meta and find a list of scientific papers on Wikidata? We got that too!
Unfortunately, hosting an open query engine comes with a bunch of limitations and provisions.
Issues Challenges
For some this may sound obvious: Wikidata is not Wikidata Query Service (and vice versa). Whether you belong to that enlightened group or not, there still may be some subtle distinctions here that aren’t immediately evident.
Wikidata itself is a service built on Wikibase. You can access any entity and see triples that comprise it. For every page like this one, you can find a page like this. They contain (mostly) the same information, but one is designed to be readable by humans, the other by applications and services (and tech-savvy humans). The latter represents the data as provided and used by WDQS —but it’s not what you’ll actually get from WDQS.
To be able to serve SPARQL queries, we first need to feed Blazegraph, WDQS’s backend RDF engine, WDQS— for our current situation, the backend RDF engine, Blazegraph—the data it needs. We use TTL (also called Turtle, because why not?) format, but we do not feed the data directly from Wikidata (or its Wikibase). The process, which we call munging, isn’t exactly complicated; at a glance, it sorts out the data, strips the types (not required for SPARQL), and validates the input.
Once prepared, the data is indexed in Blazegraph, which mostly involves heavy denormalization into specific data structures (I won’t go into detail here).
That’s it! Easy, right? Not when you’re at 11B triples, dozens of instances of Blazegraph, and a constant flow of changes —all while users are banging on your service— it isn’t.
Resolving our differences
Feeding the data into Blazegraph sounds simple enough until you learn that Blazegraph doesn’t represent the data like Wikidata does. It doesn’t contain entities; it contains triples. When an entity gets edited, it may gain some triples, and it can lose some triples. In the end, we cannot simply feed Blazegraph new triples. We need to remove stale ones as well. So how can we do that?
The answer is really easy: just check with Blazegraph to see which triples it has or not, feed in the new ones, delete the old ones and call it a day. Problem solved!
The funny thing about problems with easy solutions is that, at scale, they often don’t have easy solutions—think eating a hamburger vs eating ten. Feeding Blazegraph isn’t exactly like eating hamburgers. While you can always get nine more people into a diner (depending on your COVID-19 lockdown situation) to help with those, Blazegraph doesn’t allow more than one thread to update its indices. Additionally, parts of the process are read/write exclusive, meaning that writes interfere with reads and vice versa.
With changes constantly flowing in and Blazegraph getting slower due to the sheer size of the data and users querying the service, WDQS inevitably started to lag behind.
Keeping up with the Entities
As I mentioned in the beginning, WDQS is a very popular way of accessing Wikidata. So much so that having it lag behind Wikidata was a huge user experience issue. We had to implement some way of fixing that.
There are two things you can do if you want to synchronize two data streams, or in our case, changes made to Wikidata and data indexed in WDQS. You can speed up the slower one (WDQS) or slow down the faster one (Wikidata). While the second option sounds less than optimal, it’s also much faster to implement and takes into account multiple sources of lag – so that was the mechanism that ended up being implemented.
Most services out there implement some kind of a throttling mechanism—basically a way to make sure that the traffic doesn’t overwhelm the service. It’s no different with Wikidata. Apart from your usual query traffic throttling, it also implements a throttle on writes. Maxlag is the name of the parameter that drives that throttle. This is the maximal value of update lag between Wikidata and services that serve its data. WDQS is the biggest contributor to that lag.
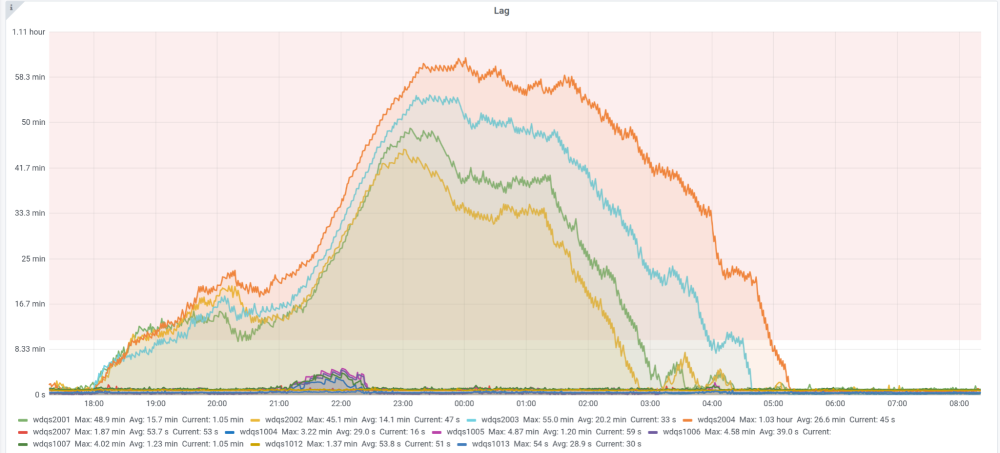
To put it bluntly, WDQS slows down how fast a bot or a user can edit Wikidata. Obviously, we mostly think about bots here—not only do they account for most of Wikidata’s traffic, but their rate of changes is also vastly larger than what humans generate. WDQS was already slowing down Wikidata’s growth and we didn’t want that.
Harder, better, faster, stronger
The current WDQS update process has its own issues, too. The main one is that it isn’t really scalable. On top of that, it is known to occasionally lose updates, mostly due to the eventual consistency of downstream data sources. We could spend time to better account for them and work on making the update process scalable, but it wouldn’t really make sense. We would still need to deal with the fact that Blazegraph doesn’t like us using it to resolve entity differences. Including all of that in an effort to improve the existing updater sounded like a full-on rewrite. We decided to do an actual full-on rewrite.
Obviously, replicating the current design of the updater made no sense —even if we worked on making it more scalable — because the design itself had fatal flows. We still hoped that we could find some low-hanging (or about 2.5 meter / 8.2 feet hanging) fruit – by making the update process work more closely with blazegraph and thus fixing some of the most pressing issues. We soon realized that tying WDQS closer to Blazegraph is the opposite of what we should be doing. It was clear that we might be moving away from that technology at some point.
Deciding to base the architecture around event streaming was a next logical step. Incoming changes are already available as streams; you can read more about them here. Not any old event processing would do, though. We wanted the new updater to actually be aware of the state of entities so it would actually know which triples to remove and which to add.
That’s how the idea of using Flink was born.
About this post
Featured image credit: File:Pika – Ladakh – 2017-08-06, Tiziana Bardelli, CC BY-SA 4.0
{kind=link}
This is part one of a three-part series. Read part two here. Read part three here.