
Building DReaMeRS: How and why we opened a datacenter in France
By Arzhel Younsi
On April 1st 2022, anyone browsing Wikipedia from Europe, Africa or the Middle-East region would have been served from our new datacenter in Marseille, France, known as “drmrs” or nicknamed “dreamers” for short. This 24 hour test marked the end of a 2 year long project, hindered by a global pandemic, chip shortages, numerous related contracts, and fluctuating supply chain issues.
Why did we need another datacenter?
Let’s rewind a bit and go over the importance of caching sites.
The Wikimedia Foundation operates its own physical servers for multiple reasons, with the main one being user privacy. The alternative of using commercial CDNs and cloud providers (with weaker privacy policies) would potentially give the providers visibility into Wikipedia user traffic.
All of Wikimedia’s content and data are stored at our two main USA datacenters in Ashburn, Virginia and the Dallas area, Texas. The issue here is that the further away users are from these two cities, the slower the web pages will load. The optic fibers which connect the World are bound to the speed of light, and multiple exchanges occur between users and our servers for a page to fully load. As there is a direct correlation between user experience and page load time, it becomes crucial for us to have servers as close to the users as possible. We call these servers “caching servers” and by extension, their locations are “caching POPs”, for point of presence. Before Marseille, we had 3 locations in San Francisco (USA), Amsterdam (The Netherlands) and the most recent one, Singapore.
Also read: How a new data center in Singapore is helping people access Wikipedia around the globe by Brandon Black
The way the caches work is straightforward:
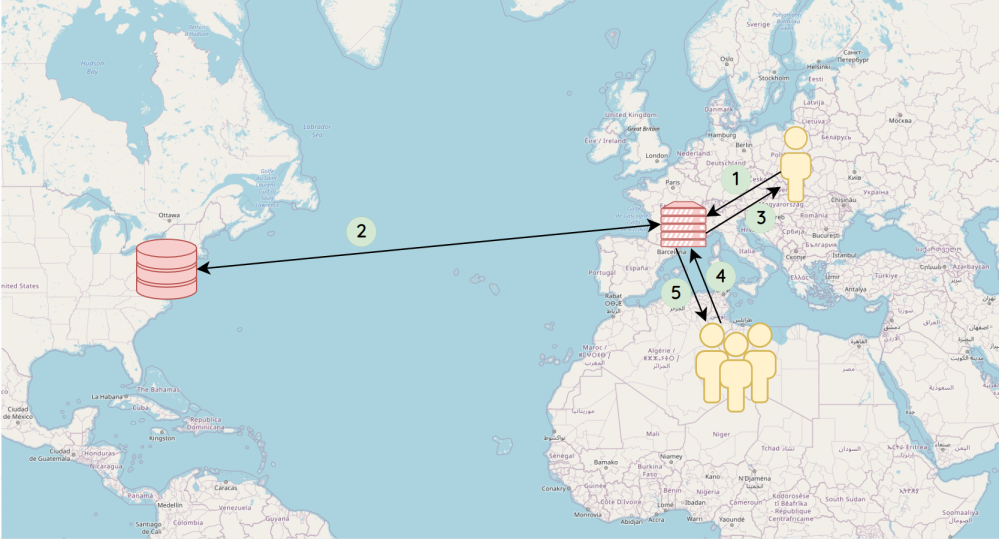
- The user’s browser requests the page to their closest cache.
- If the cache doesn’t have the page in memory, it fetches it from Ashburn/Dallas.
- It keeps it in memory and sends it back to the user.
- When the next person queries the same page
- The cache sends it back to the user, without any additional step
As you can see, step 2 would take significantly longer, but only happens once and then benefits anyone else browsing the same page. The second benefit of the caches is that they keep a “snapshot” of the page, instead of generating a web page from scratch (in the main datacenters), which would require a lot more compute power (gathering the needed information, formulas, formatting the page from the wiki syntax, etc). A metaphor could be the comparison between making a collage, and doing a photocopy of that collage. This allows us to have an efficient server to user ratio, which helps maintain a responsible environmental footprint.
So why Marseille?
Because of the amount of time and cost it takes to build out a new POP, we needed to be very thorough when choosing the location. 4 key factors made Marseille the best option: redundancy, latency, legal, and environmental impact.
Redundancy
Due to the geographical distribution of users, nearly half of Wikipedia traffic goes through the Amsterdam POP. This makes it almost “too big to fail”. Any failure or maintenance would force users to fallback on the secondary option… all the way across the Atlantic ocean, to Ashburn, worsening the user experience for millions of people. Having an alternative POP geographically close (in Europe), as well as capable of handling users going through Amsterdam, was needed.
Latency
As we can’t have servers near every single user, the next best thing we can do is aim to have the most direct routes to the users.
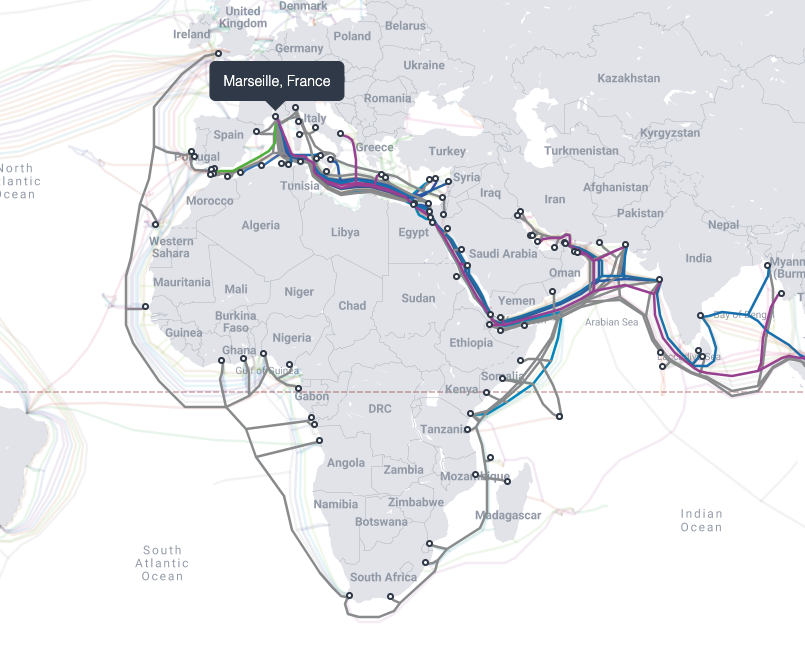
Fiber optic cables are what connects the Internet together (ISPs, content providers, enterprises, etc). On land, the cables run underground, along railroads, and highways. The larger fiber optics are found at the bottom of the ocean, connecting countries and continents.
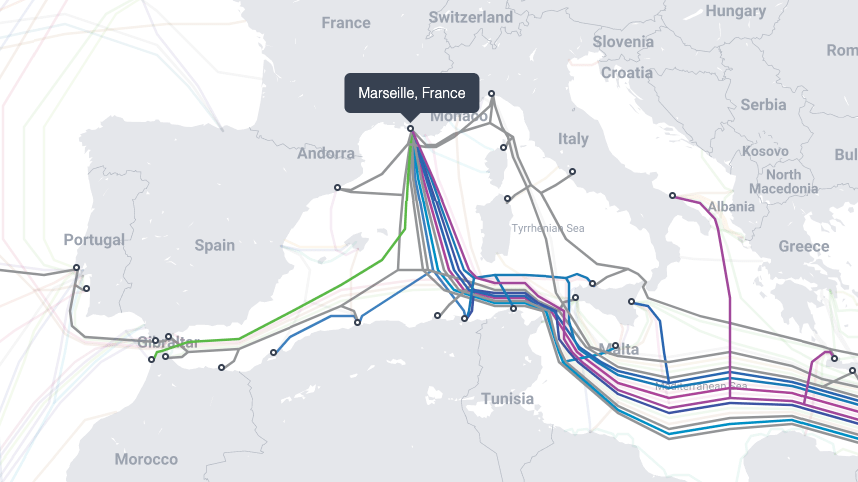
Marseille is an ideal region because it is a well connected landing station, with cables going to Africa, the Mediterranean basin, the Middle East and Asia (land cables are not shown), while also being well connected to other European countries. This helps reduce the amount of intermediary hops between users and our sites, increasing reliability while decreasing latency, thus improving the user experience.
Legal
Inherent to their function, our servers briefly capture personal information (for example which user consulted which page). For this reason, Wikimedia’s legal team extensively reviewed our shortlist of candidate countries, to ensure any risks associated with local government regulations related to data and privacy would be minimal.
Environmental impact
Even though our hardware footprint is comprised of only 25 servers, we need to be conscious of their impact in relation to the service they provide.
When a server runs, it emits heat, which needs to be dissipated. The usual way for datacenters to do so is by running large AC units that consume power. The datacenter we chose to use in Marseille to host our servers uses a river cooling technology, allowing an even lower power consumption. Additionally, France’s energy mix is quite low on carbon emissions.
Once Marseille was chosen, it was time to make it happen
Our standard rack design and hardware equipment for this caching duty fits in 2 cabinets and is capable of handling ~50% of Wikipedia’s traffic.

We lease those 2 racks from a data center service provider, also called “colocation” as we don’t occupy the entire building. They provide services, such as:
- Electricity (with backup generators), see our live electricity usage here
- Cooling
- Physical security (access control, fire suppression)
- Connectivity (the ability to run fibers to other providers)
There is of course a lot to be explained about our caching site design, from hardware to software. Each new deployment is an opportunity to improve our best practices, bringing changes to fix previously identified problems. We then backport these changes to our older POPs, usually when we refresh our hardware every 5 to 8 years.
I won’t go into the technical details, but if you’re curious, most of the code that drives our systems is public and can be found here for the server side and here for the network side, along with diagrams! The high level concept is that every component needs to be finely optimized, to handle a large amount of requests with the lowest amount of equipment, and be fully redundant, so that one faulty server or cable doesn’t cause Wikipedia to be unreachable for users.
All this effort would be useless if the servers were just sitting there on their own. These new servers need to be connected to both the Internet and our main datacenters, as we have constructed in the diagram below (Marseille is in the bottom right corner).

When choosing which providers to rely on for Internet connectivity, we take into account several factors:
- Can we connect to them in Marseille?
- Are we already a customer of theirs?
- Is their cost acceptable?
- Do they connect directly to a lot of countries/ISPs?
- Do they offer additional services? (eg. DDoS mitigation)
While we could connect to our main sites (Ashburn/Dallas) over the internet, we made the choice to use mostly dedicated circuits, also called “wavelengths service” as they tend to be more stable than the Internet. It is also critical to have “path diversity”. In other words, not having two redundant circuits next to each other, for example using the same trans-atlantic cable. As we have seen, the world can be very creative on how to damage these circuits, from construction drilling, bridges on fire to even shark attacks.
Once the circuits and equipment were fully provisioned, the new POP could then start receiving user requests. Using a technique called GeoDNS, we redirected users in small countries to Marseille, followed by larger ones. GeoDNS can be summarized as shipping a different phonebook to users, containing a different number for “Wikipedia”, depending on which country it was shipped to.
The last step was a large-scale test. We redirected all users in the countries currently using our Amsterdam caches, and shifted them to Marseille. This validated that we could sustain millions of requests per seconds at the new data center POP site. It all went fine.
Lessons learned
The Covid pandemic had 2 major impacts on this project. While we usually rely on our in-house datacenter team to physically install and cable up all the hardware equipment, they couldn’t fly out this time due to the travel restrictions. Instead they had to detail every single action that needed to be taken ahead of time: cables to plug, labels to apply, slots to put each device, for a 3rd party local contractor to do the install. We also experienced delays due to the world wide ship shortage and supply chain issues. Back in August 2021, specialized equipment such as internet routers, which were announced to ship “next month” suddenly became “March 2022”. With some escalations, the routers finally arrived slightly earlier in February, which was still six long months after the initial ETA.
What’s next? There is always some fine tuning to make. For example, we need to decide which countries should be directed to the Amsterdam POP and which should be directed to Marseille. It can be obvious for some, but others are more tricky. Here we look at the overall latency from a country to each POP site. If it’s about the same, we then look at balancing the load 50/50 between both POPs.
Whether it’s two humans chatting or someone reading a website, I’ve always found it incredible that information takes milliseconds to go between any points on the planet. But still, distance compounded with internet access quality (which varies a lot between countries) is what makes access to any information online bearable.
The principles and solutions to improve the situation you learned in this blog post apply to any Internet actor (large and small). I hope they will help anyone understand how this complex machine called The Internet works, piece by piece.
About this post
Featured image credit: submarinecablemap.com (CC BY-NC-SA 3.0)
Very informative and well written. Love to see the power graphed and being public ally accessible
Very informative and well written