

Bot or Not? Identifying “fake” traffic on Wikipedia
By Nuria Ruiz, Joseph Allemandou, Leila Zia, and MusikAnimal, Wikimedia Analytics and Research
Wikipedia, one of the largest websites in the world, gets a lot of traffic. At peak times, Wikipedia might serve as much as 10,000 pageviews per second, and as you would expect, most of these pageviews come from people reading articles to find information. Many other pageviews (about 25% of total) are from entities that we refer to as “Bots.”
“Bot” is a very overloaded term nowadays. It is used to talk about fraudulent accounts on social networks, the crawler technology that Google uses to “read” and index websites, and in the wiki world, the “bot” term is used frequently to describe automated scripts with different levels of ability that “watch” and edit Wikipedia pages. The work of these scripts is needed to fight vandalism by reverting edits that are harmful in intent, like edits that might remove most of the content of a page.
These “helpful scripts” are what we refer to as “good bots” (the word “good” here just means that they actually do meaningful work). The bots we are going to talk about in this article are —you guessed it— not so helpful, and while they are not sophisticated, they can cause some damage.
For a very innocuous example of the “damage” one of these bots can cause, take a look at the top pageview list for English Wikipedia for March 2020 right when the COVID pandemic is expanding in Europe.
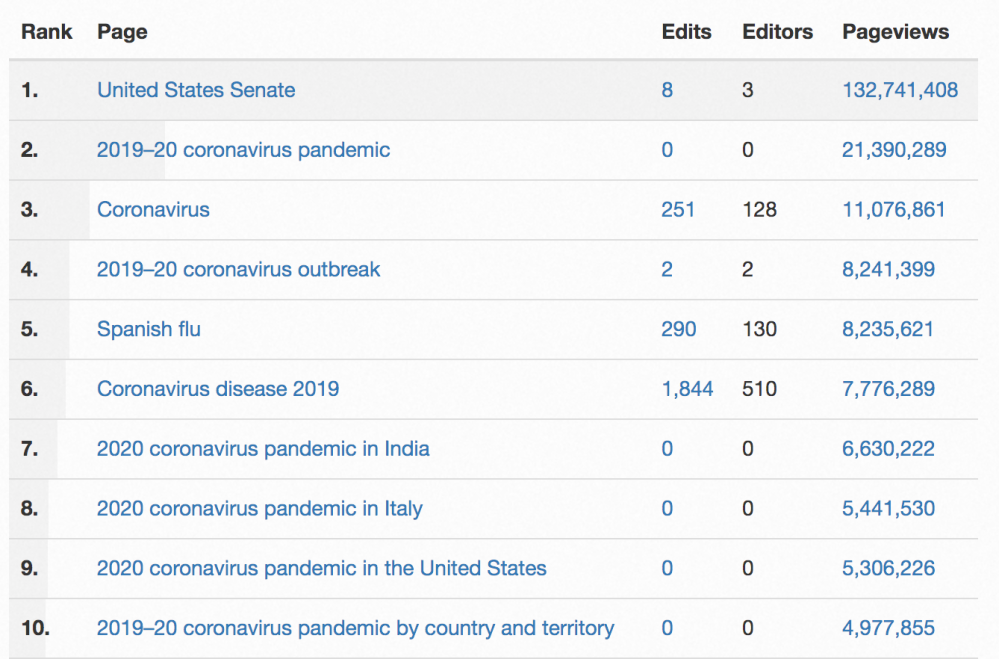
See anything strange on that list? There are more than 100 million pageviews for the “United States Senate” page, a glaring anomaly in a list that is mostly about COVID. So, what’s going on here? Well, someone is spamming Wikipedia requesting the “United States Senate” page over and over; that much is obvious. But, why? The answer is that we have no idea.
As it is often the case with big data, we can tell what is happening but not why. One possibility is that it could be someone testing their botnet by pulling a Wikipedia page. Our overall request rate metrics are public, and it might be very tempting to try to move those for some bad actors. Botnets are cheap to run nowadays and an experiment like requesting the “United States Senate” page a hundred million times might only cost a very modest amount.
Another possibility is that these are “keep-alive” requests: an application requesting some URL over and over to make sure it is online.
Other examples of pages that get quite a lot of traffic at times are the planet Venus and the List of Australian stand-up comedians. The latter has hundreds of millions of pageviews.
We call these types of actors “bot spammers.” They are actors that, while not totally legitimate, cause little harm.
The second category of bot traffic that we worry about is not so harmless.
Here’s a list of the top pageview pages from Hungarian Wikipedia in October 2019. While the list is in Hungarian it is probably easy for an English speaker to identify what stands out:
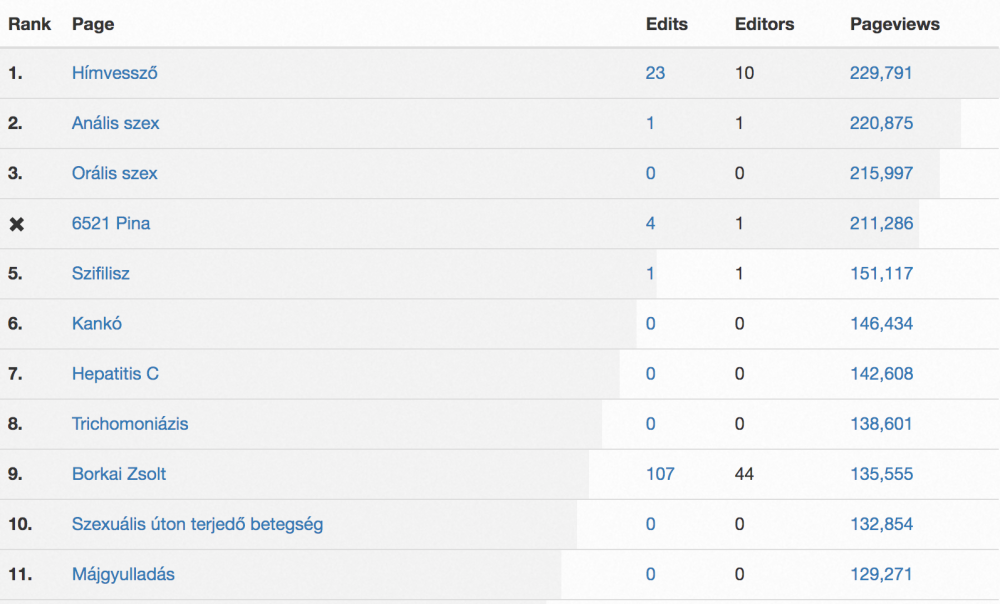
See it? There are quite a few sex and drug-related terms for starters. Not only that; the number of pageviews for those ‘questionable’ terms is very close, hovering around 200,000 for all of them. These are what we call “bot vandals.” The intent is pretty clear: vandalize the list of the top articles of a small Wikipedia. Vandals do try to do the same with larger Wikipedias like Spanish or English, but the number of requests required to get in the top 20 is a lot larger.
We have been working this past year to better identify and tag the “bot spam” traffic so we can produce top pageview lists that (mostly) do not require manual curation.
Up to April 2020, our classification for pageviews included only two types of actors: “users” and “spiders” (self-identified crawlers like Googlebot). Since all traffic not self-identified as “bot” was identified as “user,” quite a significant percentage of “bot spam” traffic was tagged as “user” traffic. This simple classification distorted our pageview numbers, as it made it seem that there was more user traffic than there really was. For example, we estimated that in 2019 between 5 to 8% of desktop pageviews in English Wikipedia tagged as “user” traffic was actually coming from “bot spammers/vandals.” That number could be as high as 800 pageviews a second. We continue processing and cataloging these requests, and from April 2020 onwards the traffic we identify as coming from spammers is tagged with the label “automated.” You can see here that it represents about 5% of total traffic.
It is interesting to notice that the effect of “bot spam” in the traffic data is not distributed equally across sites, wikis like Japanese Wikipedia seem hardly affected by spammers.
The tagging of automatic traffic is far from perfect. Some automated traffic is still being labeled as “user” pageviews and a very small percentage of user traffic might be labeled as “automated.”
This happens because classifying traffic as automated is a less trivial problem to solve than it might seem at first instance—for two reasons: data volume and semantics. The volume of data you need to comb through to “weed out” the bad requests are huge; it could be in the terabytes range for just 1 day. Also, from our example above, it is by no means obvious to a machine that the “United States Senate” page should not be in a list that mostly contains pandemic related pages as in the regular (non-pandemic) times, the Top 20 list for Wikipedia contains pages about many different topics, so outliers might not be so apparent. We decided that for our first take at the problem we would focus on computing “content agnostic features,” like ratios of requests and number of pages requested per actor per “session” to see if, with this simpler set of dimensions, we could detect the bulk of the bot spam traffic.
The community has been hard at work finding the characteristics of spammy traffic by hand for a while. For example, a key factor in distinguishing “automated” versus “real user traffic” was assessing whether pages had similar pageview numbers in the desktop and mobile versions. If a page had millions of “only desktop” pageviews it was not included in any of the top lists that were curated by hand. After a few tries, we concluded that dimensions that did not consider the nature of the page and just focused on request ratios (a.k.a “content agnostic”) were sufficient for the first iteration of the system we rolled it out in April this year. We did a careful study of how the bot spam traffic affects the most popular wikis and if you are interested, there are many plots and details in our public technical docs. For questions and comments, you can drop us a line to analytics@lists.wikimedia.org.
About this post
Featured image credit: Unknown Chinese Maker Tin Wind Up Radar Robot Front, D J Shin, CC BY-SA 3.0
{kind=link}
Cloudflare recently described their approach for this very same task: detecting bad bots, see this blog post and the other one in the category. In short they use methods like IP addresses (for well-known bots), heuristics and machine learning.