

Wikimedia’s CDN up to 2018: Varnish and IPSec
By Emanuele Rocca, Staff Site Reliability Engineer, The Wikimedia Foundation
The Wikimedia Foundation, the non-profit organization behind Wikipedia and other well known wiki-based projects, operates websites and services that are high volume and rank in the world’s top 20. We serve about 21 billion read requests per month and sustain 55 million edits to our articles. On a normal day over 90% of these read requests are served by our caching solution, our own Content Delivery Network (CDN). Like other parts of our technology stack, the CDN is based on Open Source software and is constantly evolving. During the last couple of years, we have performed various changes in terms of on-disk HTTP caching and request routing.
This 3 part series of articles will describe some of the changes, which included replacing Varnish with Apache Traffic Server (ATS) as the on-disk HTTP cache component of the CDN. ATS allowed us to significantly simplify the CDN architecture, increase our uptime, and accelerate the procedure to switch between our two primary data centers in Virginia and Texas.

Wikimedia serves its content from 2 main data centers (DC) and 3 caching-only points of presence (PoP). The two main data centers run all stateful services such as databases, job queues, application servers, and the like, as well as load balancers and HTTP caches. Instead, PoPs only run HTTP caches and the load balancers required to route traffic among them. The two main DCs are located in the United States, specifically in Virginia (short DC name: eqiad) and Texas (short DC name: codfw). The eqiad data center is the one normally serving cache misses, while codfw is a hot standby. Caching-only PoPs are available in Amsterdam (esams), Singapore (eqsin), and California (ulsfo).
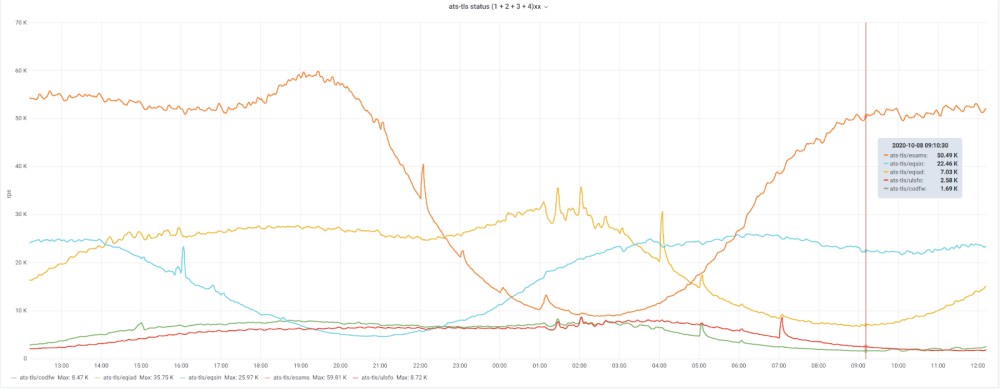
Our work is done in the open, and dashboards are no exception. See, for instance, the traffic patterns of Wikimedia DCs shown above. The CDN serves up to 150K requests per second.
Back to 2018: Varnish and IPSec
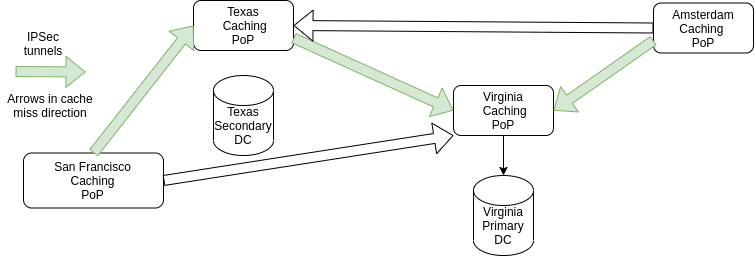
The diagram depicts the CDN architecture up to 2018. We omitted the Singapore PoP for clarity, but it works fundamentally as the California PoP.
Users are routed via GeoDNS to the PoP geographically closest to them. Their request results in a cache lookup, and in case of a cache hit the HTTP response is sent from the PoP straight back to the user, with no further processing required. In case of cache miss, instead, the request is sent further through the CDN to the next caching PoP as shown by the arrows. In case of cache misses all the way down, the request ultimately makes its way to the main primary DC.
The response goes back through the CDN (getting stored in the caches it traverses if allowed by Cache-Control and similar response headers) and finally reaches the user. To preserve the privacy of our users, HTTP requests between PoPs need to be sent encrypted. We chose to use IPSec to encrypt traffic due to the lack of outgoing HTTPS support in Varnish. Green arrows show the standard request flow through the CDN, while white paths represent IPSec connections in stand-by, to be used in case a given PoP needs to be taken down for operational reasons.
Looking more closely at what happens inside a PoP, we can see that each cache node runs three different HTTP servers: one instance of NGINX for TLS termination, one in-memory instance of Varnish for caching in RAM, and one instance of Varnish for on-disk caching. NGINX is necessary to serve HTTPS traffic given that Varnish does not support incoming HTTPS either, but can otherwise be ignored for the purposes of this article.
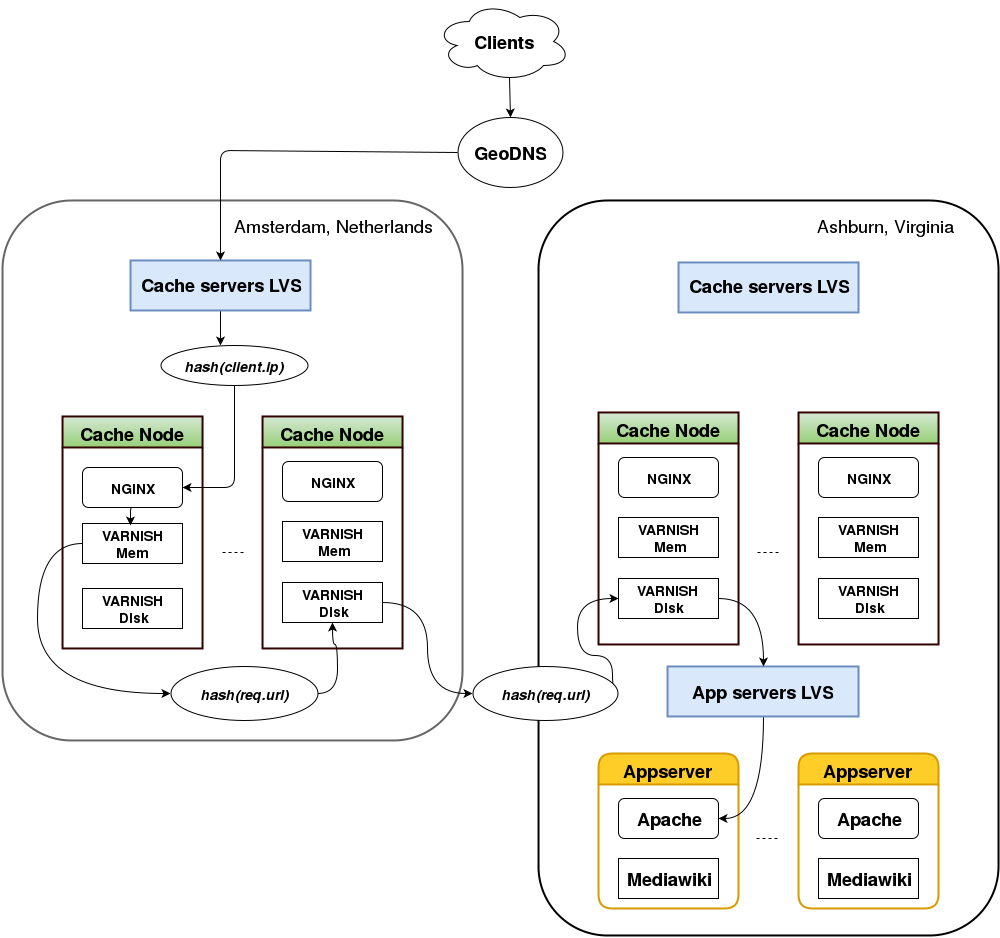
Requests are served following this simplified 4 steps model:
- Frontend cache selection
- Local backend cache selection
- Remote backend cache selection
- Request to the origin
(1) The load balancer picks a cache node by applying consistent hashing to the client IP. In case of a cache hit on the in-memory Varnish, the HTTP response is sent back directly to the user. As an optimization, the response goes back to the user without going through the load balancer. This technique is known as Direct Routing and is particularly useful for HTTP traffic, which features comparatively small requests and large responses. Cache misses are further processed by the CDN.
(2) The in-memory Varnish applies consistent hashing on the request URL to pick another cache node within the PoP (local backend) and sends the HTTP request to the on-disk Varnish instance of the node so chosen. In case of a further cache miss, request processing continues at the on-disk Varnish level in another pop (remote backend).
(3) The request is sent to another on-disk Varnish running in the next PoP. In the example above, the request goes from esams (EU, Netherlands) to eqiad (US, Virginia). The request is sent over an IPSec tunnel. In case of yet another cache miss on the remote, on-disk Varnish, the request is sent to the next remote PoP (if any), or it reaches the origin server.
(4) The origin server processes the request, and in our example, the HTTP response goes back via the remote on-disk Varnish in Virginia, the local on-disk Varnish in Amsterdam, the in-memory Varnish in Amsterdam, and finally reaches the user. If cacheable, the response is stored on the various caches it traverses, so that any later request for this object can be served from the caches instead.
Issues and the road ahead
The architecture described so far served us well for a while, though we did encounter various problems and identify areas for improvement.
Generally speaking, the hit rates on remote on-disk Varnish instances have always been very low (around 1%). Step (3) as detailed earlier in this post was there simply as a workaround for lack of TLS support in Varnish and could be avoided using an HTTPS-capable caching proxy instead.
Furthermore, the on-disk cache instances were affected by serious scalability and reliability issues. Varnish supports various types of storage backends for its cache contents. Up to version 3, the persistent storage backend was our backend of choice and worked very well in our usage scenario: it worked reliably and allowed us to store cache objects on disk. Further, the cache was persistent, in the sense that we could restart Varnish without losing the cache.
The persistent storage backend was deprecated in Varnish version 4, and replaced in the proprietary version of Varnish by a storage backend with similar features and called Massive Storage Engine. FOSS users were thus left with the option of using the file storage backend, which had two major drawbacks: (1) no support for persistence (2) scalability issues.
The second problem, in particular, was occurring after a few days of production use: a sizable number of requests would result in 503 errors, and normal operation could be resumed only by restarting Varnish. As a bandaid, we introduced a cron-job restarting Varnish on a weekly basis. Unfortunately, this frequency of restarts did not prove to be sufficient, and we had to resort to restarting Varnish twice a week to reduce the frequency of user-facing outages. The issue turned out to be a known architectural limitation of the file storage engine. After several debugging sessions we concluded that it was time to start looking for alternatives.
As a viable replacement for Varnish we identified Apache Traffic Server: an Apache Software Foundation project used and developed by many large organizations including Apple, Verizon, Linkedin, and Comcast. A migration to ATS would solve our two major pain points with Varnish: it supports persistent storage on-disk reliably, as well as incoming and outgoing HTTPS.
In the next post, we will describe the architectural changes made possible by migrating the on-disk component of our CDN to Apache Traffic Server.
About this post
This is Part 1 of a 3 part series. Read Part 2. Read Part 3.
Featured image credit: Earth from low orbiting satellite, Public domain.
{kind=link}
Not every administrator runs infrastructure that facilitates such discoveries—but certainly most administrators stand to benefit from the knowledge said discoveries bring. Thank you for getting the word out. I look forward to the rest of the series.