

Wikimedia’s CDN: the road to ATS
By Emanuele Rocca, Staff Site Reliability Engineer, The Wikimedia Foundation
Wikimedia Foundation, the non-profit organization behind Wikipedia and other well known wiki-based projects, operates websites and services that are high volume and rank in the world’s top 20. We serve about 21 billion read requests per month and sustain 55 million edits to our articles. On a normal day over 90% of these read requests are served by our caching solution, our own Content Delivery Network (CDN). Like other parts of our technology stack, the CDN is based on Open Source software and is constantly evolving. During the last couple of years, we have performed various changes in terms of on-disk HTTP caching and request routing.
This 3-part series of articles describes some of the changes, including the replacement of Varnish with Apache Traffic Server (ATS) as the on-disk HTTP cache component of the CDN. ATS allowed us to significantly simplify the CDN architecture, increase our uptime, and accelerate the procedure to switch between our two primary data centers in Virginia and Texas.
Introduction
In Part 1 we described the architecture of Wikimedia’s CDN up to 2018 when Varnish was used for both in-memory (frontend) and on-disk (backend) caches. The article pointed out a few issues we had with Varnish as the on-disk backend cache software; such issues made us look for alternatives. Now it’s time to see why we chose Apache Traffic Server as the replacement for Varnish, how this choice greatly simplified our CDN architecture, the challenges we faced, and what the migration entailed.
Why ATS
While looking for an alternative, we defined the following requirements:
- Reliable disk-backed persistent storage backend
- TLS support
- Ability to scale up to ~10K requests per second per host
- Easily extensible
- Battle-tested
Being able to reliably and persistently store objects on disk, as well as support for TLS, are requirements that came directly as a response to the issues we encountered with Varnish. The figure of 10 thousand requests per second in terms of expected scalability is due to the observation that traffic on our busiest frontend cache nodes reaches a peak request rate of over 10 thousand rps when PURGE traffic is taken into account:

Although we do expect a significantly lower rate on backend caches, it’s still important to sustain up to the peak traffic handled by frontends at the backend layer too; in case of frontend caches being restarted (or crashing due to software bugs!), the whole dataset is lost, and the backend caches need to protect the origins from all the resulting cache misses.
Varnish can be configured by writing code in a language called VCL (Varnish Configuration Language). This feature provides great flexibility and allows us to implement very specific mechanisms at the CDN level. For instance, our Varnish deployment on backend caches was doing things such as setting response headers based on URL patterns. The software replacing Varnish in our infrastructure needed to provide the same, or similar, flexibility.
Last but not least, the operational experience gained by running a large CDN for years highlighted the fact that HTTP on the public internet is a wild beast with multiple edge cases and exceptions; clients come in all shapes and forms, with middle-boxes often making matters worse. Only reverse proxy cache implementations deployed for a few years by large CDNs have seen enough conflicting interpretations of the standards and unusual behaviors to give us some confidence that they might do the right thing when needed.
There are unfortunately not many serious contenders in the caching HTTP reverse proxy space: Squid and Traefik being among the most interesting ones. Squid is the software we were using early on in Wikimedia’s history before moving to Varnish; the main reasons for moving away from it included the difficulty of extending its functionalities, lack of IPv6 support, and sub-optimal CPU usage. Traefik is a young and promising project, but it does not support caching yet, and in any case, it is clearly not as battle-tested as we would like it to be.
Apache Traffic Server, instead, seemed to tick all the boxes:
- Advanced support for on-disk caching
- Inbound and outbound TLS
- Known large deployments by organizations such as Apple and Comcast
- Around since 1996 as Inktomi Traffic Server
- Fully extensible in Lua
We thus decided to deploy a test ATS cluster and send our PURGE traffic to it in order to gain some basic operational experience and observe the behavior of those test instances. Initial testing was successful, so we went to the drawing board and rejoiced at the architectural simplifications we could introduce.
New architecture with ATS
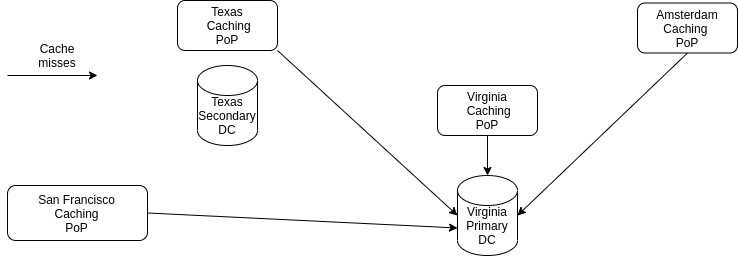
Thanks to Traffic Server’s support for TLS, the new CDN architecture is now much simpler than what it looked like with Varnish as an on-disk cache. IPSec can be removed entirely, and caches in different PoPs do not need to be aware of each other any longer. Cache misses in any of the caching PoPs can now be served directly from the origin servers, without having to go through the caches running in another datacenter.
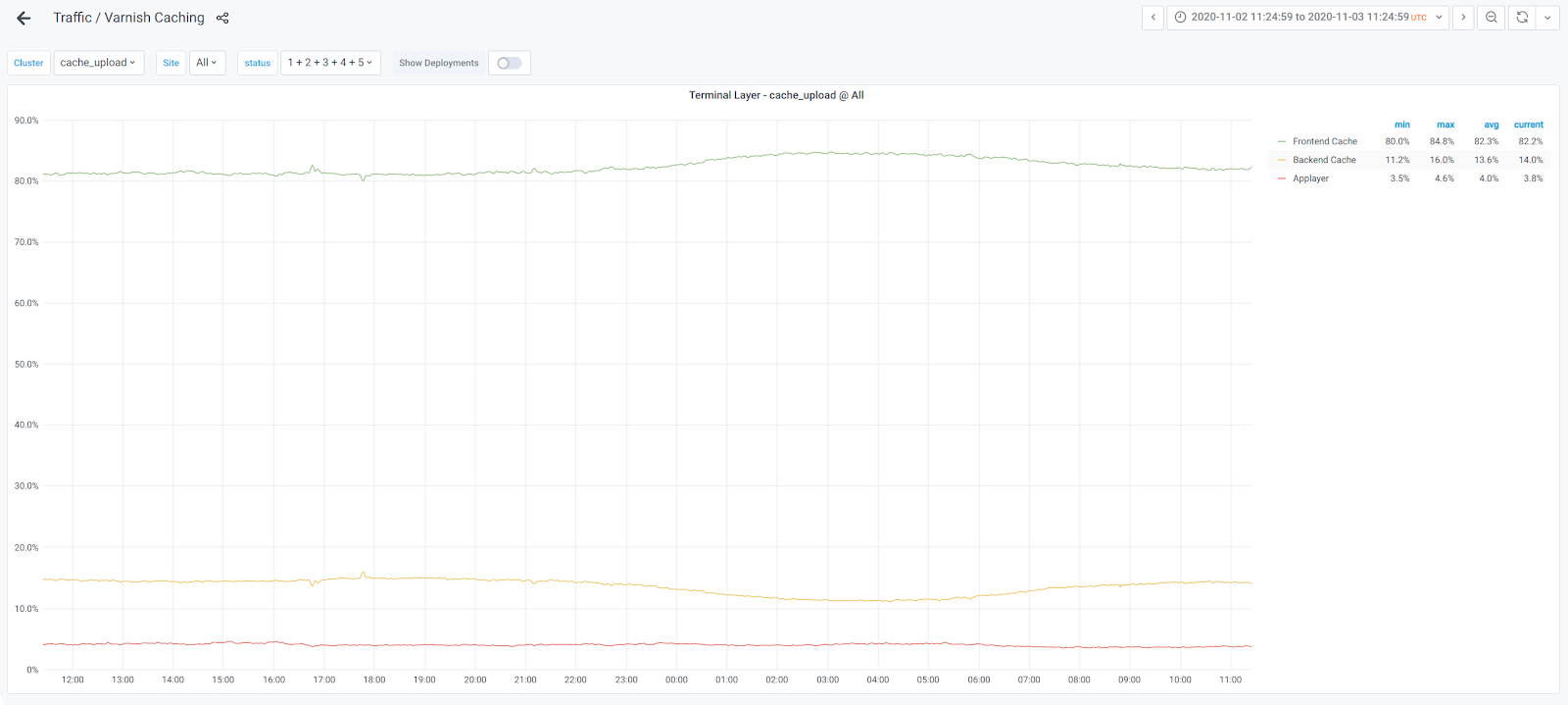
As the first step in the migration, we targeted the so-called cache_upload cluster. Wikimedia’s PoPs are logically divided into two cache clusters, called cache_text and cache_upload. The former is responsible for textual content such as HTML, javascript, CSS, and so forth. The latter is instead dedicated to multimedia files, mostly images but also audio and video files. Other than having fairly different object size distributions, with files on cache_text being generally smaller and cache_upload files larger, the two clusters also differ in how likely origin server responses are to be cached. Multimedia files can essentially always be cached, as their content does not depend on which user is requesting the resource. HTML responses are instead sometimes user-dependent, for example in the case of logged-in users. This is reflected by the hit rate figures: on cache_text, depending on the time of day between 83-88% of the requests are served by the CDN, while on cache_upload the rate is normally much higher, around 97%.
Additionally, the origin servers behind cache_text run a diverse set of applications and software stacks; their behavior is at times surprising, when not slightly buggy. On the contrary, cache_upload is responsible for only two applications: (1) OpenStack Swift, the object store where all our multimedia content resides, and (2) Kartotherian – the service powering https://maps.wikimedia.org. Because of these reasons, we’ve decided to proceed with the migration of cache_upload first.
Migration
The areas of work required to migrate the first cluster to ATS included:
- Porting VCL code to Lua
- URI Path Normalization
- Disable on-disk request logging, yet allow log inspection
- Thundering herd mitigation
The VCL code used by cache_upload Varnish backends was split across three files: (1) upload-backend.inc.vcl.erb, (2) upload-common.inc.vcl.erb, (3) wikimedia-backend.vcl.erb, and (4) wikimedia-common.inc.vcl.erb. We used the ATS Lua plugin to implement the required functionalities in Traffic Server. As an example, the script x-mediawiki-original.lua is responsible for setting the X-Mediawiki-Original response header based on the request URI:
--[[
Set X-MediaWiki-Original based on the request URI.
For example, the following request URI:
/wikipedia/commons/thumb/3/37/Home_Albert_Einstein_1895.jpg/200px-Home_Albert_Einstein_1895.jpg
Will result in X-MediaWiki-Original being set to:
/wikipedia/commons/3/37/Home_Albert_Einstein_1895.jpg
]]
require 'string'
function gen_x_mediawiki_original(uri)
if string.match(uri, "^/+[^/]+/[^/]+/thumb/[^/]+/[^/]+/[^/]+/[0-9]+px-") then
prefix, postfix = string.match(uri, "^(/+[^/]+/[^/]+/)thumb/([^/]+/[^/]+/[^/]+).*$")
ts.client_response.header['X-MediaWiki-Original'] = prefix .. postfix
end
end
function remap_hook()
local uri = ts.client_request.get_uri() or ''
gen_x_mediawiki_original(uri)
end
function do_remap()
ts.hook(TS_LUA_HOOK_SEND_RESPONSE_HDR, remap_hook)
return 0
endMore work went into porting the rest of the VCL to a global Lua plugin, default.lua. Traffic Server did not expose two pieces of information required in order to effectively port VCL to Lua: (1) whether or not a given origin server response can be cached, and (2) if it can be, the calculated age of the object—for how long can it be stored in cache before being considered stale. The first part was relatively straightforward to fix: the C++ API did provide a function for exactly the purpose of determining cacheability, TSHttpTxnIsCacheable. What was needed was patching the Lua plugin to expose this function. We did that in our own ATS Debian packages, and later worked with the Traffic Server project to get the patch merged. The second piece of information was a bit harder to obtain, in that not even the C++ API had a function returning the calculated object age. We thus proceeded to add such function, TSHttpTxnGetMaxAge, and of course expose it via the Lua plugin too. We first applied the change to our internal packages and later upstreamed it to ATS core, as well as the Lua plugin.
Another important feature implemented using the Traffic Server Lua plugin is URI path normalization. A given Uniform Resource Identifier (URI) can have multiple valid representations. For example, the following URIs correspond to the Wikipedia page Steve_Fuller_(sociologist):
- https://en.wikipedia.org/wiki/Steve_Fuller_(sociologist)
- https://en.wikipedia.org/wiki/Steve_Fuller_%28sociologist)
- https://en.wikipedia.org/wiki/Steve_Fuller_%28sociologist%29
Though all the above representations are valid, we must ensure that the CDN converts them to one, univocal representation. One reason is ensuring that, if Steve_Fuller_(sociologist) is cached, a request for Steve_Fuller_%28sociologist%29 results in a cache hit— it’s the same page after all! More importantly, having a single representation is crucial to ensure cache coherence. Upon modification, we need to invalidate all cached copies of the article. If we were to allow two different representations of a given URI to have their own cache entry, then when the article for Steve_Fuller_(sociologist) is updated we would have the problem of ending up with stale versions of the article Steve_Fuller_%28sociologist%29 in cache. A detailed explanation of the URI Path Normalization problem and what it meant in the context of our migration to Apache Traffic Server is available on the relevant Phabricator task. The Lua plugin normalize-path.lua is our current solution to the problem.
Requests logging was another important issue to tackle. Varnish takes a very interesting approach to logging, using a shared memory segment onto which detailed information about requests and responses is appended, instead of writing anything to disk. Various programs such as varnishlog and varnishncsa can then be used to read, filter, and present the logs at runtime when needed. ATS follows the traditional design of writing logs to disk, allowing to specify complex log formats and providing facilities for log rotation. In our setup, request logs are streamed via Kafka to various analytics systems, and we are not interested in keeping request logs on the cache servers themselves. Avoiding the significant disk I/O introduced by logging thousands of requests per second to disk is furthermore desirable. ATS does allow you to write logs to a named pipe instead of regular files, which seems like the right thing to do in order to avoid writing logs to disk while still being able to inspect them on demand, but (1) there must be a reader program consuming the logs from the pipe at all times, and (2) UNIX pipes cannot have more than one reader fetching the same data concurrently. To address this, we wrote a system called fifo-log-demux, based on nginx-log-peeker.
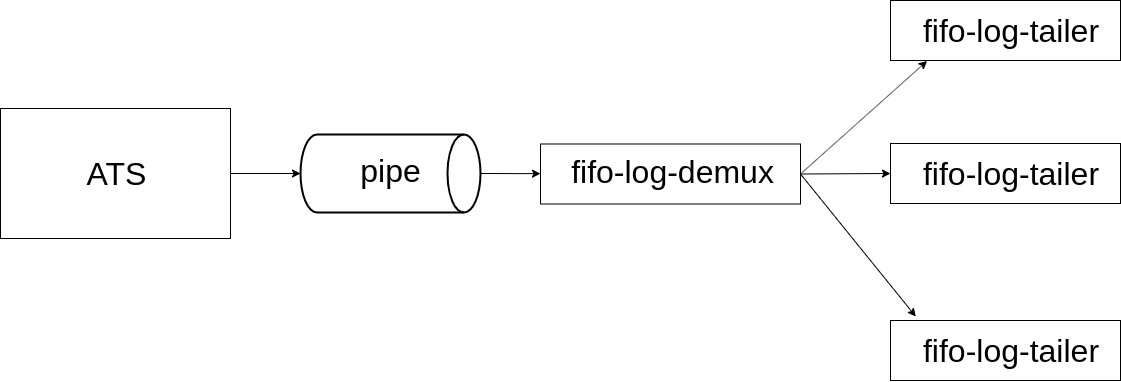
We configure ATS to log to a named pipe and deploy fifo-log-demux as a daemon constantly reading from said pipe, while listening on a UNIX domain socket for connection from multiple clients, called fifo-log-tailer in the diagram above. Clients can specify a regular expression and will receive all log entries matching the regex till they’re stopped. By following this approach, multiple operators can inspect log entries at runtime using a simple CLI tool, and we could write various clients generating Prometheus metrics from the logs with mtail. One such example is atsbackendtiming.mtail.
The next and final article of this series will illustrate the thundering herd problem and the relevant mitigations made available by ATS. Further, it will describe the procedure we use to switch from the primary datacenter in Virginia to the secondary in Texas, and how the migration from Varnish to ATS drastically simplified it.
About this post
This post is part 2 of a 3 part series. Read Part 1. Read Part 3.
Featured image credit: On the road, Death Valley, specchio.nero, CC BY-SA 2.0
.jpg){kind=link}
Thank you very much for this post, as well as the information that other businesses are focusing on technology.