

Wikimedia’s CDN: datacenter switchover
By Emanuele Rocca, Staff Site Reliability Engineer, The Wikimedia Foundation
Wikimedia Foundation, the non-profit organization behind Wikipedia and other well known wiki-based projects, operates websites and services that are high volume and rank in the world’s top 20. We serve about 21 billion read requests per month and sustain 55 million edits to our articles. On a normal day over 90% of these read requests are served by our caching solution, our own Content Delivery Network (CDN). Like other parts of our technology stack, the CDN is based on Open Source software and is constantly evolving. During the last couple of years, we have performed various changes in terms of on-disk HTTP caching and request routing.
This three-part series of articles describes some of the changes, including the replacement of Varnish with Apache Traffic Server (ATS) as the on-disk HTTP cache component of the CDN. ATS allowed us to significantly simplify the CDN architecture, increase our uptime, and accelerate the procedure to switch between our two primary data centers in Virginia and Texas.
Introduction
In Part 1 we described the architecture of Wikimedia’s CDN up to 2018 when Varnish was used for both in-memory (frontend) and on-disk (backend) caches and pointed out some of the issues we had with Varnish. Part 2 focused on the reasons why we chose Apache Traffic Server as the replacement for Varnish, and what the migration entailed. This article illustrates the thundering herd problem and the approach followed by ATS to mitigate it. Further, it will describe the procedure we use to switch from the primary datacenter in Virginia to the secondary in Texas, and how the migration from Varnish to ATS drastically simplified it.
Thundering herd
One of the main goals of a Content Delivery Network is to reduce the load on application servers by serving as many HTTP responses as possible from cache and only sending traffic to the application if strictly necessary. For example, certain responses cannot be stored on a shared cache because they are specific to a given user — in such circumstances, there is no alternative for the CDN but to send traffic to the application servers. Responses that can be shared among different users should instead be cached.
What happens if multiple clients request the very same page at the same time, and the page is not cached yet? A naive HTTP caching software would consider all such requests independently, perform multiple cache lookups, find that the object is not in cache and send each and every request to the application servers; for particularly popular content, the resulting load can overwhelm the application. This sort of issue is known as Cache stampede or Thundering herd.
A better approach consists of realizing that the multiple concurrent requests are really for the same object, sending one single request to the application while putting all clients on hold, caching the object, and finally sending the same cached response to all clients. This is exactly the approach followed by Varnish by default, a technique known as request coalescing in Varnish terminology.
Apache Traffic Server also provides mechanisms to reduce the thundering herd problem: it identifies multiple concurrent requests for the same object using a functionality called Read While Writer and makes all but one request wait using Open Read Retry Timeout. We observed the behavior of ATS in production using a SystemTap script, coalesce_retries.stp and tuned the ATS settings proxy.config.http.cache.max_open_write_retries and max_open_read_retries accordingly. With the work illustrated in part 2 out of the way, and this mitigation for the cache stampede problem in place, the migration to ATS could be considered complete.
Once per year we perform a test during which all cache misses and generally uncacheable traffic are served from the secondary data center in Texas instead of the primary in Virginia. The test is done to ensure that, with minimal downtime, all the wikis can still function even in case of catastrophic failures in the primary DC. The migration from Varnish to ATS for cache backends simplified the switchover procedure greatly, let’s see how.
DC switchover in 2018 (Varnish)
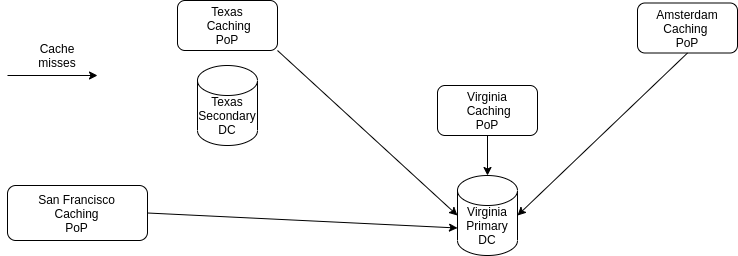
The CDN architecture up to 2018 was as follows:
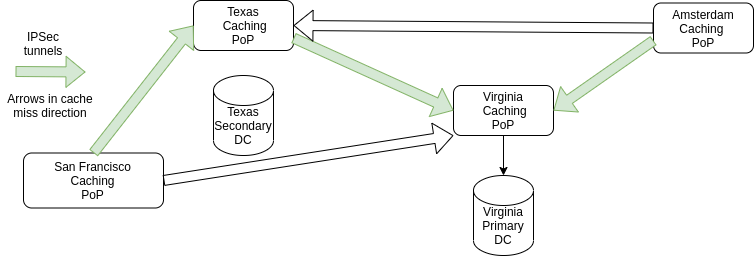
All cache misses in, say, the Amsterdam PoP were routed to other caches in the Virginia PoP, and from there to the application layer. The whole procedure was described in detail in Part 1, so please see that article for the details if you’ve missed it!
Due to this architecture, serving traffic from the secondary DC in Texas instead of the primary in Virginia required multiple steps:
- All caches routed via the Virginia DC had to be moved to the one in Texas
- Caches in the Virginia DC had to be sent to the one in Texas instead of going straight to the application layer
- Caches in the Texas DC had to be routed straight to the application layer
Visually:
All cache servers, like the rest of Wikimedia’s infrastructure, are configured via Puppet. Due to lack of TLS support in Varnish, caches in one DC could not be routed straight to the application layer in another but had to be routed via other caches. Further, Varnish does not look up the DNS record of the configured origin servers at runtime; it only does it once at startup or when the VCL configuration is reloaded. For these reasons, performing the 3 switchover operations mentioned above required multiple Puppet commits and running various commands in the right order on the right servers.
The YAML data structure cache::route_table had to be modified as follows to route all Amsterdam (esams) caches to Texas (codfw):
cache::route_table:
eqiad: 'codfw'
codfw: 'eqiad'
ulsfo: 'codfw'
esams: 'eqiad' # Replace 'eqiad' with 'codfw' here
eqsin: 'codfw'
The change had to be code reviewed, merged, and applied to all cache nodes in Amsterdam with the following command: sudo cumin ’A:cp-esams’ ’run-puppet-agent -q’.
See the article on Wikitech for details about Cumin, our own automation and orchestration framework.
After this step, the configuration of all individual application backends had to be changed similarly. For example, in the case of Mediawiki and the API:
appservers:
backends:
# comment eqiad , uncomment codfw
eqiad: 'appservers.svc.eqiad.wmnet'
# codfw: 'appservers.svc.codfw.wmnet'
api:
backends:
# comment eqiad, uncomment codfw
eqiad: 'api.svc.eqiad.wmnet'
To avoid routing loops, where a cache in Virginia (eqiad) would be sent to a cache in Texas (codfw) with those in codfw still routed to eqiad, it was crucial to merge this change with Puppet disabled on all relevant cache servers, then run Puppet on all Texas nodes first, ensure all got updated correctly, and only at that point proceed with re-enabling and running Puppet on the Virginia nodes to route them to Texas.
During the switchover, all wikis have to be set temporarily as read-only. The operations mentioned in this section took 2 of the 7 minutes of read-only time during the 2018 switchover.
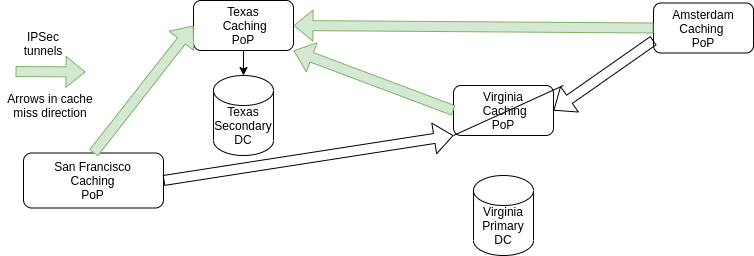
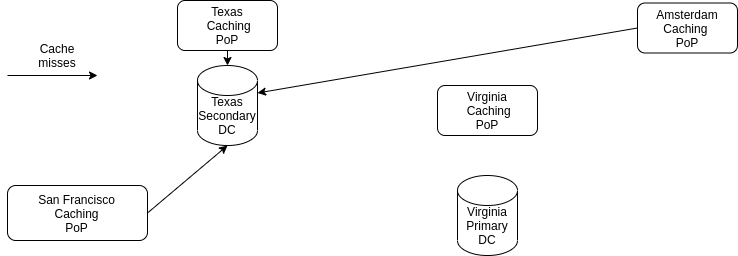
DC switchover in 2020 (ATS)
The new architecture with ATS (see Part 2) looks like this:
Thanks to the following nice facts about Apache Traffic Server:
- It supports TLS, thus caches in one remote data center (say Amsterdam) can be routed straight to the application layer without compromising on users privacy
- It resolves DNS records at runtime, so no commands must be executed on cache servers to change their origins
Switching the primary data center now requires only a bunch of DNS changes: returning the IP address of the application servers in Texas instead of those in Virginia. DNS changes are applied almost immediately, significantly reducing the switchover read-only time.
Conclusion
In this three part series, we have described the architecture of Wikimedia’s own Content Delivery Network, and explained how the migration from Varnish to ATS as the cache backend software simplified the CDN architecture, removed a frequent source of outages, and improved the primary data center switchover procedure.
About this post
This post is part 3 of a 3 part series. Read Part 1, and Part 2.
Featured image credit: Wikimedia Foundation Servers, Victor Grigas, CC BY-SA 3.0
{kind=link}
omg thank you very much, this is very helpful because I need more references to implement CDN with ATS and VARNISH. thank you very much
Moh Ali.
What is the considerations behind wikimedia builds own CDN instead of using commercial CDN service (especially the ones offering free service)?
Thank you for the series. We use ats for video cache and it does well the job.
I have some doubts regarding coalesce, can you share please the tuning parameters regarding thundering heard? Many thanks.