

Perf Matters at Wikipedia in 2016
Thumbor shadow-serving production traffic
Wikimedia Commons is our open media repository. Like Wikipedia and its other sister projects, Commons runs on the MediaWiki platform. Commons is home to millions of photos, documents, videos, and other multimedia files.
MediaWiki has a built-in imagescaler that, until now, we used in production as well. To improve security isolation, we started an effort in 2015 to develop support in MediaWiki for external media handling services. We choose Thumbor, an open-source thumbnail generation service, for Wikimedia’s thumbnailing needs.
During 2016 and 2017 we worked on Thumbor until it was feature complete and able to support the same open media formats and low-memory footprint as our MediaWiki setup. This included contributions to upstream Thumbor, and development of the wikimedia-thumbor plugin. We also fully packaged all dependencies for Debian Linux. Read more in The Journey to Thumbor (3-part series), or check the Wikitech docs.
– Gilles Dubuc.
Exclude background tabs
During routine post-deployment checks we found the p99 First Paint metric regressed from 4s to 20s. That’s quite a jump. The median and p75 during the same time period remained constant at their sub-second values.
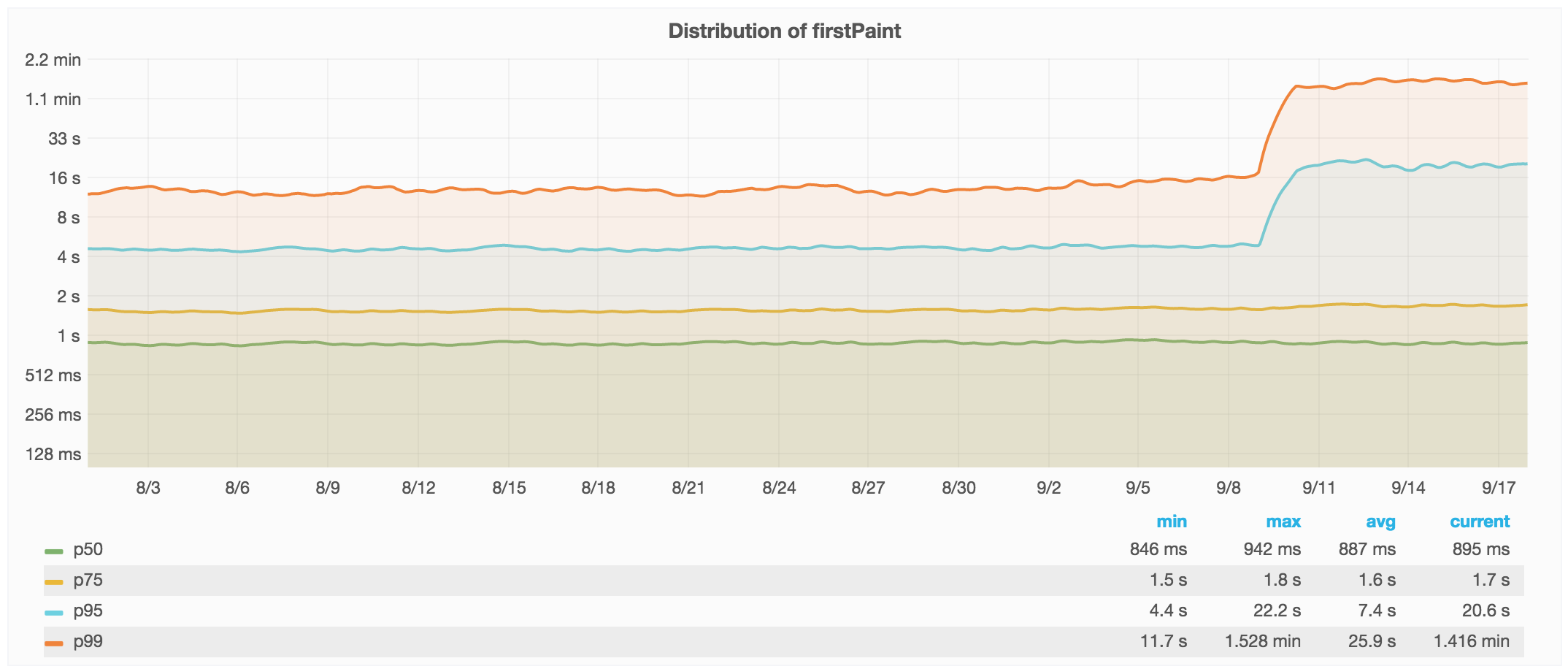
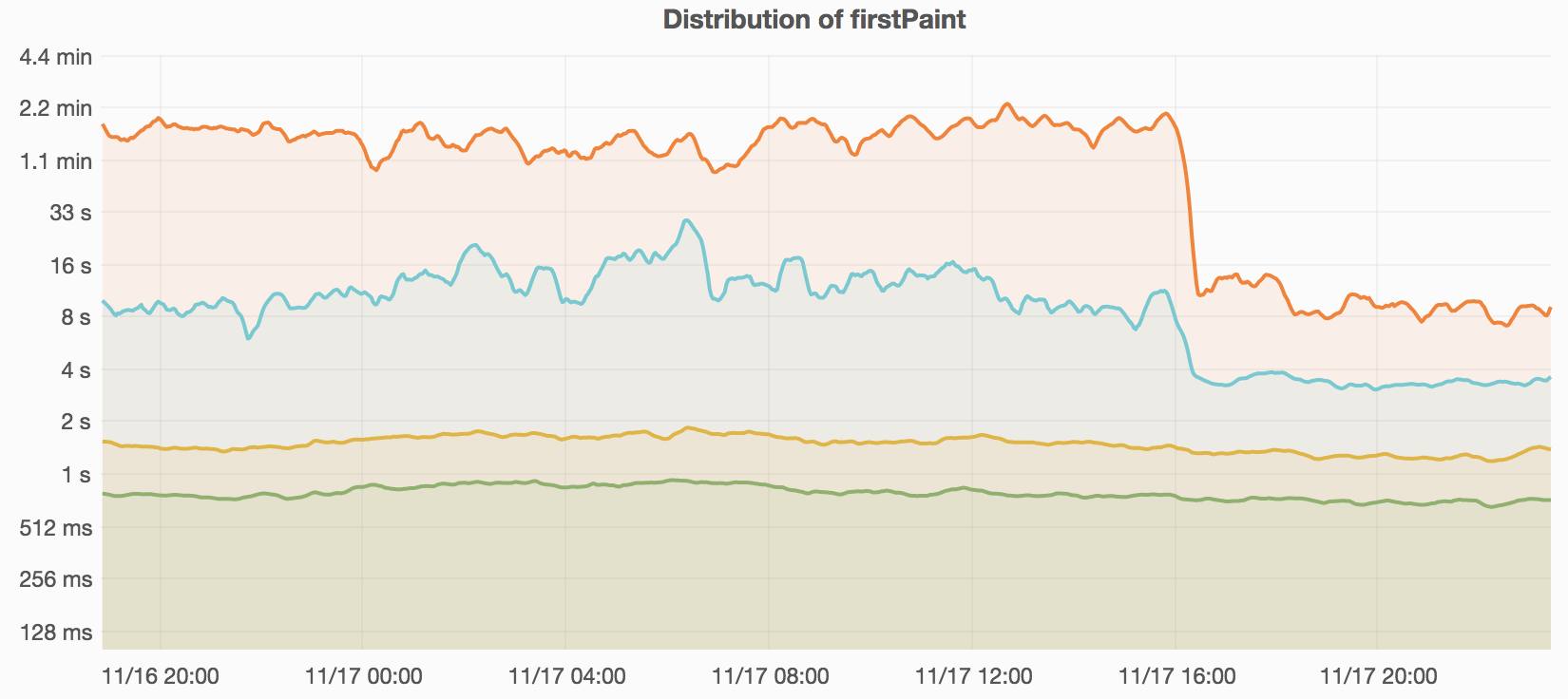
After an investigation we learned that page load time and visual rendering metrics are often skewed in visually hidden browser tabs (such as tabs that are open in the background). The deployment had refactored code such that background tabs could deprioritize more of the rendering work. Rather than revert this, we decided to change how MediaWiki’s Navigation Timing client collects these metrics. We now only sample pageviews in browser tabs that are “visible” from their birth until the page finishes loading.
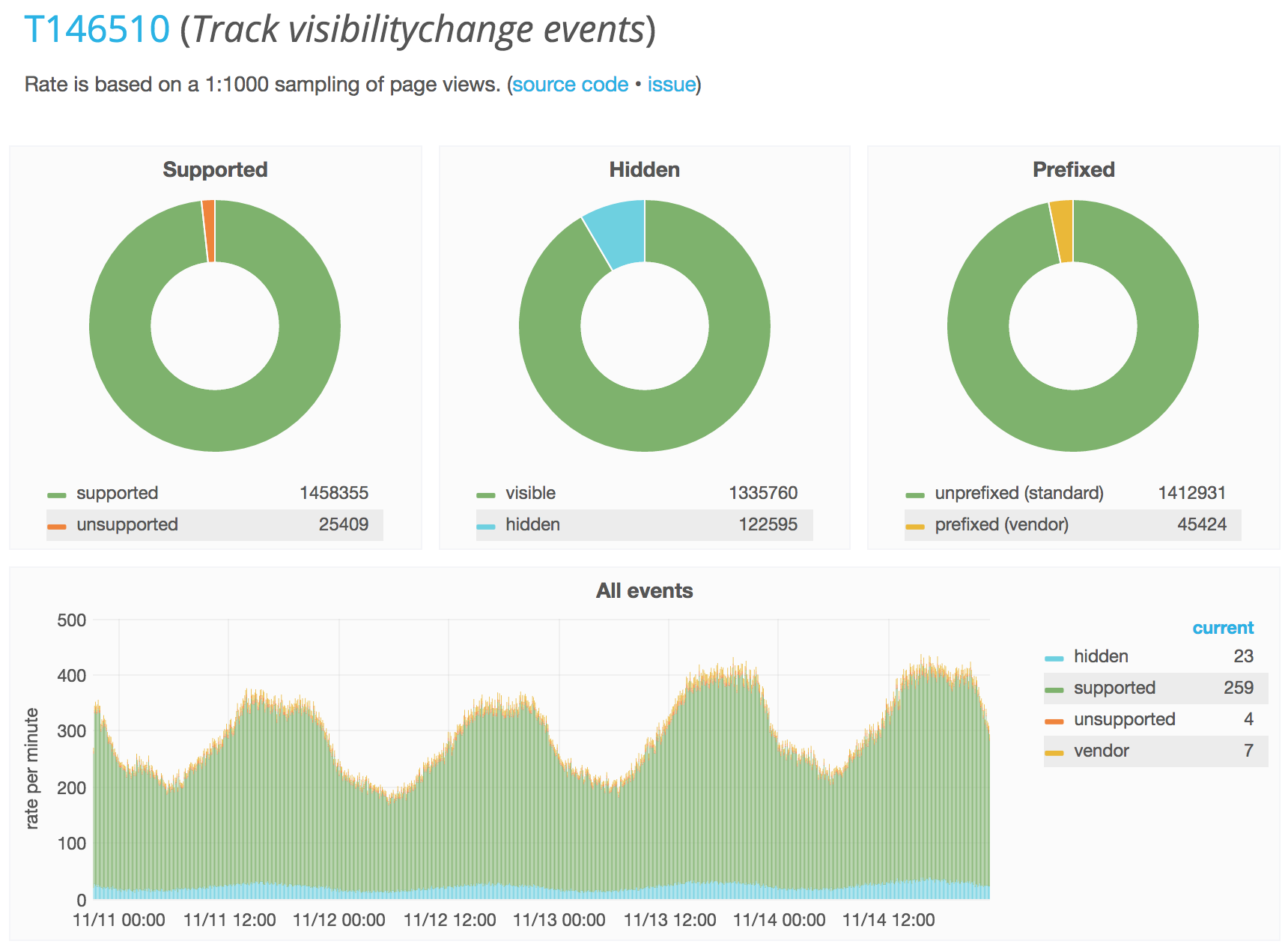
To understand why background tabs had such an impact on our global metrics, we also ran a simple JS counter for a few days. We found that over a three-day period, 8.4% of page views in capable browsers were visually hidden for at least part of their load time. (Measured using the Page Visibility API, which itself was available on 98% of the sampled pageviews.)
– Peter Hedenskog and Timo Tijhof.
Performance Inspector goes Beta
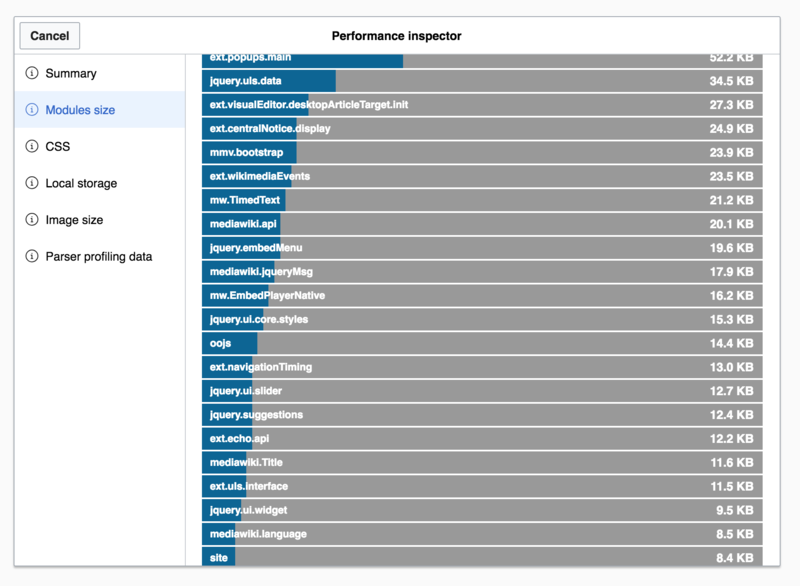
We had an idea to improve page load time performance on Wikipedia by providing performance metrics to editors through an in-article modal link (T117411). By using the Performance Inspector, tech-savvy Wikipedians could use this extra data to inform edits that make the article load faster. At least, that was the idea.
It turns out that in reality it’s hard for users to distinguish between costs due to the article content and costs of our own software features. It was hard for editors to actually do something that made a noticeable difference in page load time. We discontinued the Performance Inspector in favor of providing more developer-oriented tools.
— Peter Hedenskog.
Hello, HTTP/2!
Deploying HTTP/2 support to the Wikimedia CDN significantly changed how browsers negotiate and transfer data during the page load process. We anticipated a speed-up as part of the transition, and also identified specific opportunities to leverage HTTP/2 in our architecture for even faster page loads.
We also found unexpected regressions in page load performance during the HTTP/2 transition. In Chrome, pageviews using HTTP/2 initially had a slower Time to First Paint experience when compared to the previous HTTP/1 stack. We wrote about this in HTTP/2 performance revisited.
– Timo Tijhof and Peter Hedenskog.
Stylesheet-aware dependency tracking
2016 saw a new state-tracking mechanism for stylesheets in ResourceLoader (Wikipedia’s JS/CSS delivery system). The HTML we send from MediaWiki to the browser, references a bundle of stylesheets. The server now also transmits a small metadata blob alongside that HTML, which provides the JS client with information about those stylesheets. On the client side, we utilize this new metadata to act as if those stylesheets were already imported by the client.
Why now
MediaWiki is built with semantic HTML and standardized CSS classes in both PHP-rendered and client-rendered elements alike. The server is responsible for loading the current skin stylesheets. We generally do not declare an explicit dependency from a JS feature to a specific skin stylesheet. This is by design, and allows us to separate concerns and give each skin control over how to style these elements.
The adoption of OOUI (our in-house UI framework that renders natively in both PHP and JavaScript), got to a point where an increasing number of features needed to load OOUI both as stylesheet for server-rendered elements, but also potentially load OOUI for (unrelated) JS functionality such as modal interactions elsewhere on the page. These JS-based interactions can happen on any page, including on pages that don’t embed OOUI elements server-side. Thus the OOUI module must include stylesheets in this bundle. This would have caused the stylesheet to sometimes download twice. We worked around this issue for OOUI, through a boolean signal from the server to the JS client (in the HTML head). The signal indicates whether OOUI styles were already referenced (change 267794).
Outcome
We turned our workaround into a small general-purpose mechanism built-in to ResourceLoader. It works transparently to developers, and is automatically applied to all stylesheets.
This enabled wider adoption of OOUI, and also applied the optimization to other reusable stylesheets in the wider MediaWiki ecosystem (such as for Gadgets). It also facilitates easy creation of multiple distinct OOUI bundles without developers having to manually track each with a boolean signal.
This tiny capability took only a few lines of code to implement, but brought huge bandwidth savings; both through relative improvements as well as through what we prevented from being incurred in the future.
Despite being small in code, we did plan for a multi-month migration (T92459). Over the years, some teams had begun to rely on a subtle bug in the old behavior. It was previously permitted to load a JavaScript bundle through a static stylesheet link. This wasn’t an intended feature of ResourceLoader, and would load only the stylesheet portion of the bundle. Their components would then load the same JS bundle a second time from the client-side, disregarding the fact that it downloaded CSS twice. We found that the reason some teams did this was to avoid a FOUC (first load the CSS for the server-rendered elements, then load the module in its entirety for client-side enhancements). In most cases, we mitigated this by splitting the module in question in two: a reusable stylesheet and a pure JS payload.
– Timo Tijhof.
One step closer to Multi-DC
Prior to 2015, numerous MediaWiki extensions treated Memcache (erroneously) as a linearizable “black box”. A box that could be written to in a naive way. This approach, while somewhat intuitive, was based on dated and unrealistic assumptions:
- That cache servers are always reachable for updates.
- That transactions for database writes never fail, time out, or get rolled back later in the same request.
- That database servers do not experience replication lag.
- That there are no concurrent web requests also writing to the same database or cache in between our database reads.
- That application and cache servers reside in a single data center region, with cache reads always reflecting prior writes.
The Flow extension, for example, made these assumptions and experienced anomalies even within our primary data center. The addition of multiple data centers would amplify these anomalies, reminding us to face the reality that these assumptions were not true.
Flow became among the first to adopt WANCache, a new developer-friendly interface we built for Memcached, specifically to offer high resiliency when operating at Wikipedia scale.
Replication lag was especially important. In MySQL/MariaDB, database reads can enjoy an “isolation level” that offers session consistency with repeatable reads. MediaWiki implements this by wrapping queries from a web request in one transaction. This means web requests will interact with one consistent and internally stable point-in-time state of the database. For example, this ensures foreign keys reliably resolve to related rows, even when queried later in the same request. However, it also means these queries perceive more replication lag.
WANCache is built using the “cache aside” and “purge” strategies. This means callers let go of the fine-grained control of (problematically) directly writing cache values. In exchange, they enjoy the simplicity of only declaring a cache key and a closure that computes the value. Optionally, they can send a “purge” notification to invalidate a cache key during a (soon-to-be-committed) database write.
Instead of proactively writing new values to both the database and the cache, WANCache lets subsequent HTTP requests fill the cache on-demand from a local DB replica. During the database write, we merely purge relevant cache keys. This avoids having to wait for, and incur load on, the primary DB during the critical path of wiki edits and other user actions. WANCache’s tombstone system prevents lagged data from getting (back) into a long-lived cache.
Read more about the Flow case study or Multi-DC MediaWiki.
– Aaron Schulz.
Improve database resilience
We made numerous improvements to database performance across the platform. This is often in collaboration with SRE and/or with the engineering teams that build atop our platform. We regularly review incident reports, flame graphs, and other metrics; and look for ways to address infra problems at the source, in higher-level components and MediaWiki service classes.
For example, the incident where a partial outage due to database unavailability, was caused by significant network saturation on the Wikimedia Commons database replicas. The saturation occurred due to the PdfHandler service fetching metadata from the database during every thumbnail transformation and every access to the PDF page count. This was mitigated by removing the need for metadata loads from the thumbnail handler, and refactoring the page count to utilize WANCache.
Another time we used our flame graphs to learn one of the top three queries came from WikiModule::preloadTitleInfo. This DB query uses batching to improve latency, and would traditionally be difficult to cache due to variable keys that each relate to part of a large dataset. We applied WANCache to WikiModule and used the “checkKeys” feature to facilitate easy cache invalidation of a large category of cache keys, through a single operation; without need for any propagation or tracking.
Read more about our flame graphs in Profiling PHP in production at scale.
– Aaron Schulz.
Further reading
About this post
Featured image credit: Long exposure of highway by PxHere, licensed under Creative Commons CC0 1.0.
{kind=link}