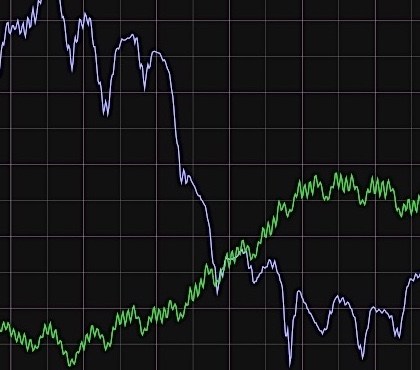
Deploying HTTP/2 support to the Wikimedia CDN significantly changed how browsers negotiate and transfer data during the page load process. We found regressions in performance during the transition and are sharing the lessons we learned.
The Wikimania 2022 Hackathon is a free, online event where anyone interested in Wikimedia technology can work together on projects, learn new skills, and meet other technical contributors. Don’t miss this opportunity to come together with other Wikimedia technical community members!
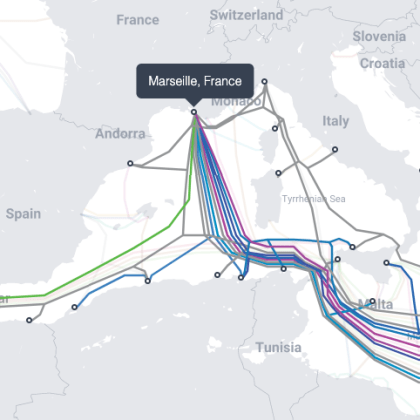
Content delivery networks (CDNs) are one of the modern building blocks of the Internet. This blog post highlights a recent addition to Wikimedia’s CDN setup.
The Wikimedia Developer Portal guides technical audiences to key documentation and community resources. By organizing links into thematic sections focused on developer tasks, it helps people more easily find information about Wikimedia technology.
MediaWiki allows editors to contribute with geospatial content. Learn more about the internals of the map technology we use and the improvements introduced.
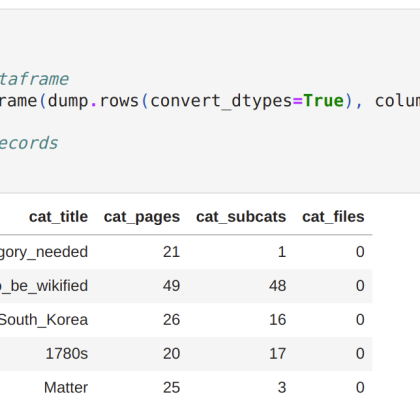
MediaWiki page titles are the primary identifiers for all wiki content – learn how they are validated, normalized and parsed and what it took to do so in Rust.